 Jing Yang
Jing Yang Jiahui Lu1
Jiahui Lu1 Guochun Shen
Guochun Shen- 1Tiantong National Station for Forest Ecosystem Research, School of Ecological and Environmental Sciences, East China Normal University, Shanghai, China
- 2Shanghai Institute of Pollution Control and Ecological Security, Shanghai, China
- 3Chengdu Institute of Biology, Chinese Academy of Sciences, Chengdu, China
Intraspecific trait variation (ITV) is common feature of natural communities and has gained increasing attention due to its significant ecological effects on community dynamics and ecosystem functioning. However, the estimation of ITV per se has yet to receive much attention, despite the need for accurate ITV estimation for trait-based ecological inferences. It remains unclear if, and to what extent, current estimations of ITV are biased. The most common method used to quantify ITV is the coefficient of variation (CV), which is dimensionless and can therefore be compared across traits, species, and studies. Here, we asked which CV estimator and data normalization method are optimal for quantifying ITV, and further identified the minimum sample size required for ±5% accuracy assuming a completely random sample scheme. To these ends, we compared the performance of four existing CV estimators, together with new simple composite estimators, across different data normalizations, and sample sizes using both a simulated and empirical trait datasets from local to regional scales. Our results consistently showed that the most commonly used ITV estimator (CV1= σsample/μsample), often underestimated ITV—in some cases by nearly 50%—and that underestimation varies largely among traits and species. The extent of this bias depends on the sample size, skewness and kurtosis of the trait value distribution. The bias in ITV can be substantially reduced by using log-transforming trait data and alternative CV estimators that take into consideration the above dependencies. We find that the CV4 estimator, also known as Bao's CV estimator, combined with log data normalization, exhibits the lowest bias and can reach ±5% accuracy with sample sizes greater than 20 for almost all examined traits and species. These results demonstrated that many previous ITV measurements may be substantially underestimated and, further, that these underestimations are not equal among species and traits even using the same sample size. These problems can be largely solved by log-transforming trait data first and then using the Bao's CV to quantify ITV. Together, our findings facilitate a more accurate understanding of ITV in community structures and dynamics, and may also benefit studies in other research areas that depend on accurate estimation of CV.
Introduction
Intraspecific trait variation (ITV) is the overall difference in traits values among conspecific individuals in one or more traits, such as height, specific leaf area, and wood density (Albert et al., 2011). Such variation widely exists in nature (Darwin, 1859; Siefert et al., 2015) and has large ecological effects on population dynamics (Agashe, 2009; Abbott and Stachowicz, 2016), community assembly (Siefert and Ritchie, 2016; Griffiths et al., 2018), and ecosystem functioning (Bukowski and Petermann, 2014; Souza et al., 2017). Because of its wide ranging ecological consequences, the ecological effects of ITV and the extent of ITV are increasingly attracting research attention (Des et al., 2018).
Accurate estimation of ITV is essential for fully understanding species distributions and abundances from a trait-based perspective because the absolute extent of ITV is thought to be closely linked with species tolerances to the abiotic environment and responses to neighborhood interactions (Clark, 2010). Specifically, it is hypothesized that, because species' responses to the environment manifest through functional traits, the higher the ITV of a species is, the more diverse abiotic environments the species may be able to adapt to (Umaña et al., 2015). Therefore, if we underestimate ITV, species' distributions across heterogeneous environments might be underestimated as well (Helsen et al., 2017). Consequently, their resilience to current environmental fluctuation may be underestimated and their extinction risk overestimated. Similarly, the magnitude of ITV is thought to be linked with niche overlap among species (Li et al., 2017). Large ITVs may increase species niche overlap and interactions (Williams et al., 2017) and that in turn promote or hamper species coexistence (Hart et al., 2016). If estimated ITVs of co-occurring species were biased, we likely largely bias the estimation of interspecific interactions and lose accuracy in the predictions of species abundance and coexistence status. However, compared to the current enthusiasm surrounding the ecological effects of ITV, little attention has been paid to the estimation of ITV itself (but see Mitchell and Bakker, 2014). At present, it is still unclear whether ITV estimation is unbiased and accurate enough to facilitate reasonable ecological inferences.
Most current studies use the coefficient of variation (CV = σ/μ) to quantify the absolute extent of ITV and evaluating whether ITV varies among species or traits, and ultimately in thinking about the response of populations or communities to environmental change (see our literature review in Tables 1 and S1). As a single value summary statistic, CV is less informative than other quantifications of ITV (e.g., parametric probability distribution), but it is simple and its definition does not require ad hoc assumptions of the underlying probability distributions for each trait. Importantly, CV is unitless, and thus offers a convenient way to directly compare variation (e.g., trait-based niche width) among species with different abundances under various environments (Helsen et al., 2017). For example, comparative studies have shown a positive relationship between species ITV and niche breadth (Clark, 2010): species with larger ITV tend to have larger geographical ranges than species with smaller ITV (Brown, 1984).
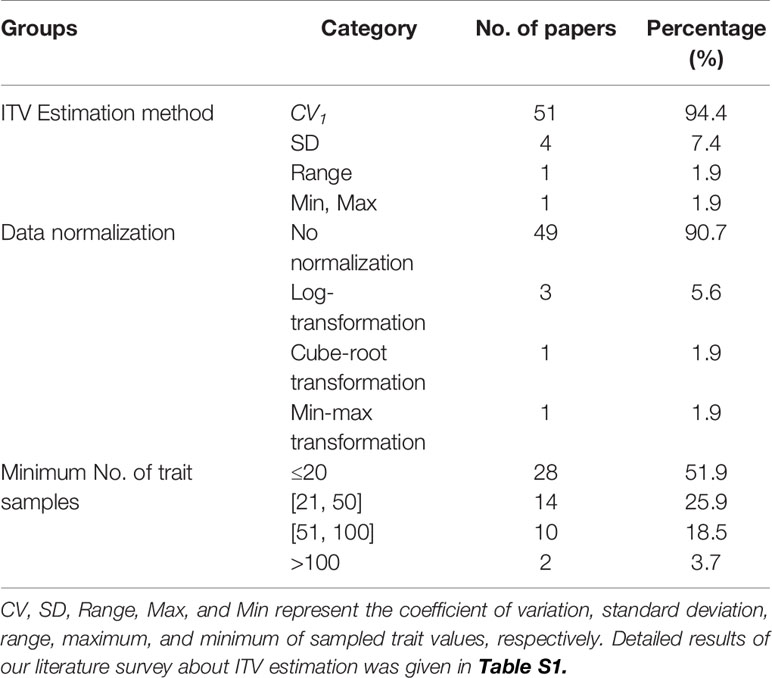
Table 1 A summary of CV estimation methods, data normalizations and the minimum number of samples for each species used in conventional studies.
Despite the widely appreciated merits of CV and the importance of accurate ITV estimation, it is less well-known that the most commonly used CV estimator (CV1= σsample/μsample) is biased (Sokal and Rohlf, 1995), which means that the real ITV of an entire population of a species cannot be accurately estimated from trait samples when the sample size is small (e.g., 10). Other CV estimators do exist (e.g., Bao, 2009) and may perform better than CV1, but no studies, to our knowledge, have compared the performance of these CV estimators using large empirical trait datasets, which may be considerably different from commonly used simulated data. For example, large trait datasets often contain few extreme values, and it is not clear if these values bias the ITV estimations and whether there are data normalization methods could reduce these biases.
In addition to choosing a suitable CV estimator and data normalization method, few studies quantify the minimum sample size needed for accurate estimation of ITV. As reviewed by Bastias et al. (2017), and here (Table 1), fewer than 50 individuals were sampled per species in more than 77.7% of reviewed studies. Although measuring traits on a very large number of individuals per species is not always feasible, such a small sample size may introduce large bias into the estimation of ITV and subsequent ecological inferences. For arbitrary trait distributions, the bias of CV1 has an approximate and negative reciprocal relationship with sample size (Bao, 2009). This reveals the possibility that the true ITV in many contemporary studies is likely underestimated by CV1, and this underestimation may be more serious when the sample size is small (<10). Despite the potential importance of ITV in many ecological disciplines, no study has yet examined the effect of sample size. Moreover, because traits have various distributions and often take extreme values, whether there exist bounds for the minimum sample size of ITV estimation remains largely unknown.
Here, we attempt to address the above knowledge gaps and improve the estimation of ITV by answering the following three questions: (i) To what extent the current estimations of ITV are biased? (ii) Are there more accurate estimators and data transformations for estimating ITV? (iii) Are there prescriptive rules for identifying the minimum sample size needed for a given level of accuracy (here ±5%)? To answer these questions, we reviewed the previous literature and evaluated the performance of CV estimators using simulated and empirical trait datasets. Finally, we evaluated the accuracy of the best performing ITV estimator across various sample sizes.
Materials and Methods
Surveying Methods Commonly Used to Estimate ITV
To find the most commonly used methods for the quantification of ITV in recent literature, we searched the Web of Knowledge (http://thomsonreuters.com/web-of-knowledge/) in Sep. of 2019 for research articles containing the topic “intraspecific variation”, or “intraspecific variability”, or “individual variation” (including wildcard terms such as vari*, var*, and intra*) in the past 19 years, from 2000 to 2019. Studies that only used quantitative statistical tests such as ANOVA, Levene's test, and linear mixed-effects models to analyze or account for ITV were omitted, because comparing ITV among populations, species, studies, and regions requires knowledge about the absolute extent of ITV. We downloaded the full text of each remaining article and checked if and how ITV was calculated. Specifically, we summarized the absolute and relative number of studies that used each ITV estimation method, data normalization scheme, and the minimum sample sizes for each species in our literature survey (Tables 1 and S1). These data revealed that a great majority (94%) of researchers used CV1 (see below) as their estimator of ITV.
Existing CV Estimators
There are four CV estimators (regression estimators of the CV such as described by Archana and Rao (2011) were ignored here). The first estimator, CV1, is
where σsample and μsample are the standard deviation and mean of a given sample, respectively. This is the most commonly used estimator of CV despite its bias (Sokal and Rohlf, 1995). If the value of a trait follows the normal distribution, the bias of CV1 is -CV1/(4N) (Sokal and Rohlf, 1995), where N is the sample size. Thus, the second estimator, CV2, is formulated by subtracting CV1 with the bias term:
Because CV2 is derived under the assumption of a normal distribution, it may underperform when trait values are not normally distributed. Breunig (2001) proved mathematically that the bias of CV1 also depends on the skewness and kurtosis of the distribution of trait values. Therefore, Breunig (2001) and Bao (2009) proposed two approximate estimators, CV3 and CV4 (also called Bao's CV estimator), respectively, which do not assume any specific trait distribution:
where N is the sample size, and γ1 and γ2 are the Pearson's measures of skewness and kurtosis of the trait sample distribution, respectively.
New Composite CV Estimators
In our performance evaluation of CV estimators (below), we found that CV3 and CV4—which are only approximate estimators of CV—often underestimate or overestimate the population CV in our simulation and empirical data (see Figures 1A, S1A, S1E, S2I, S4A, and S4E). Therefore, we propose four simple composite estimators, CV5, CV6, CV7, and CV8. CV5 and CV7 are defined as the arithmetic and geometric means of CV2 and CV3, respectively, and CV6 and CV8 are defined as the arithmetic and geometric means of CV2 and CV4, respectively.
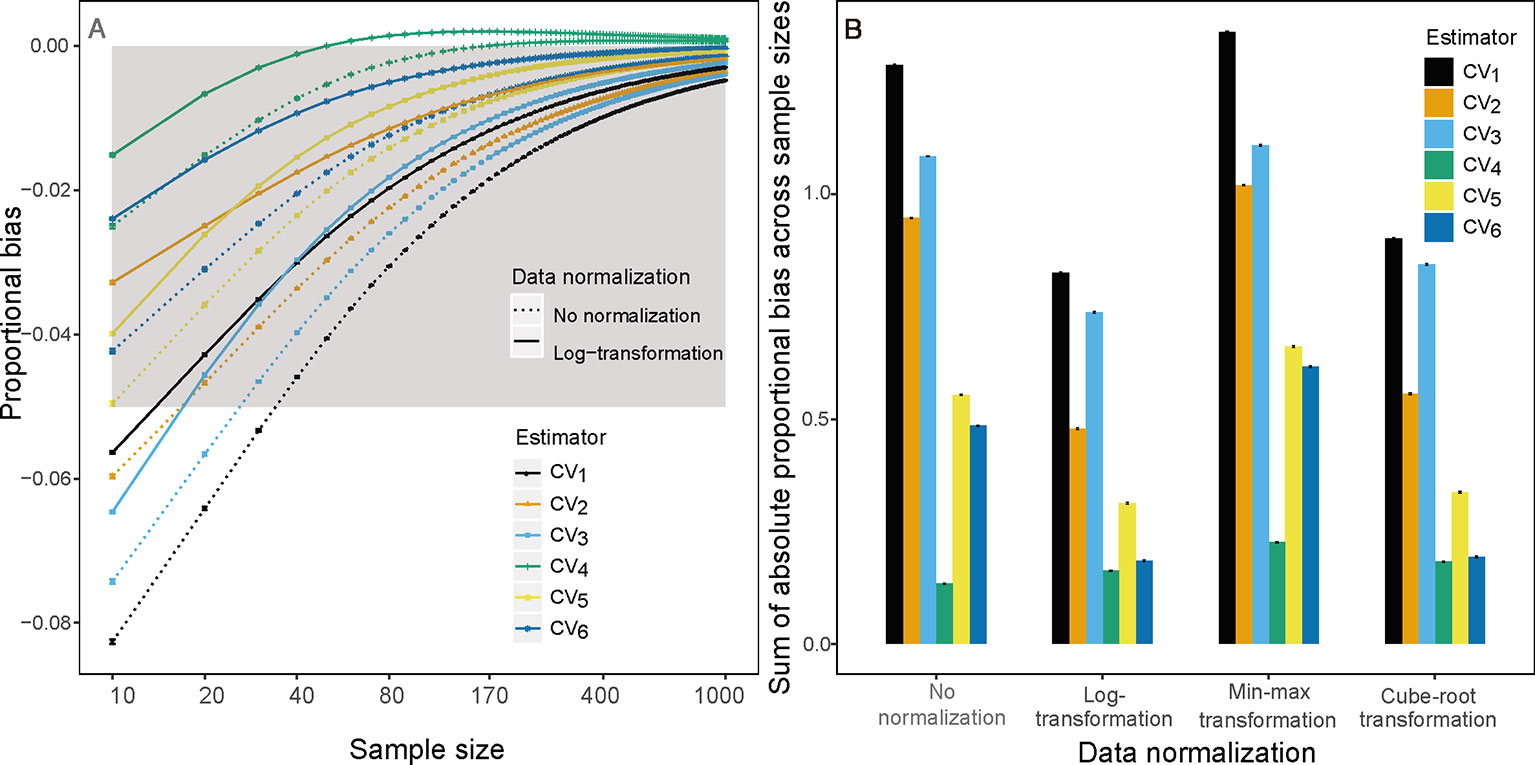
Figure 1 (A) Proportional bias on sample size k(k∈{10,20,30,…1,000}) based on raw (dotted line) and log-transform (solid line) simulated trait values and (B) sum of absolute proportional bias across all sample size for the ith(i∈{1,2,3,4,5,6})CV estimator based on raw, log-transform, min-max transform and Cube-root transform simulated trait values. Gray area is the region in which the absolute mean proportion of bias is less than 0.05.
We found CV7 and CV8 have almost identical performance compared to CV5 and CV6, respectively, so we will only present the results of CV5 and CV6 in the remainder of the text. Note that CV3 and CV4 were derived without any assumption of trait value distribution, thereby their composite estimators, CV5 and CV7, also make no assumptions of the true trait value distribution.
Identifying the Minimum Sample Size
Accurate estimation of ITV not only depends on the choice CV estimator and data transformation, but also on sample size. Generally, the accuracy of any estimator increases with the sample size. Therefore, it is crucial to know how many samples are sufficient to reach a specific accuracy requirement in the estimation of ITV. Here, we defined the minimum sample size ki,min for estimator i as the minimum integer k that reaches ±5% accuracy of the ITV estimation. Because different traits of species may have different distributions, we calculated ki,min for each trait of each selected species separately.
Performance Evaluation With Simulated Trait Data
To find the optimal CV estimator and data transformation, we evaluated the performance of the above estimators using simulated trait data. First, 200 trait pools were generated by simulation. Specifically, for each trait pool, 9,520 trait values were drawn from a gamma distribution with a shape parameter β1 and a scale parameter β2, which were two independent random variables following a uniform distribution from 1 to 10 and from 5 to 30, respectively. The ranges of β1 and β2 were determined by fitting empirical trait value distributions using a gamma distribution for each trait of each species with abundance ≥100 in our trait plot (see details of the trait plot below). We chose the gamma distribution here because its domain, like empirical functional trait value, is always positive and its shape is flexible enough to model various distributions of traits. Additionally, empirical trait data often have a few (4.8% on average) extreme large values, which are defined here as trait values greater than three standard deviations from the mean. These extreme values may have large impacts on the accuracy of CV estimators. Therefore, we added 480 extreme large values to each simulated trait pool. The extent of the extreme value follows a truncated exponential distribution from mean+3*standard deviation of the trait pool to infinity and parameter λ equals 1. Note that we recognize that we cannot simulate all possible trait distributions observed in natural communities; here, we tried as best as possible to cover a large portion of the ranges of empirical trait distributions.
For each sample size k(k∈N and {N: 10, 15, 20, … 400}), k trait values were sampled from each simulated trait pool and CVi,k was calculated for each CV estimator i(i∈{1,2,3,4,5,6}). The mean CV, , and its standard error were calculated from 9,999 replicates of sample size k. Then the bias of the ith estimator under sample size k was defined as , where CVtrue is the population CV that is known in our simulated data. Note that CVtrue is only required in our performance evaluation, and is not demanded in the estimation of ITV. The sign of B(i,k) indicates whether CVi,k under- or overestimates ITV. To facilitate estimator comparison, we calculated the proportion of bias (PB(i, k) = B (i, k)/CVtrue) for each sample size and estimator combination, and total absolute bias for each estimator.
Our literature review further found that three types of data normalization methods are used in the estimation of ITV in conventional studies (Table 1). The first is min-max transformation defined as (x-xmin)/xmax, where x is the raw trait value and xmin and xmax are the minimum and maximum values of all sampled trait values, respectively. The second method is log-transformation with the natural logarithm base. For trait with values smaller than 1, 1 was added to all values of that trait before log-transformation. The last is cube-root transformation. To compare the effect of data normalizations on ITV estimation, PB(i,k) and TPB(i) were calculated for the raw trait data and three types of data normalizations for each CV estimator.
Performance Evaluation With Empirical Trait Data
The performance of all the above estimators and data normalizations were also evaluated using three individual-based trait datasets, each representing a different geographic scale. For each dataset, we used the same sampling scheme as in the simulated data: 9,999 replicates were drawn with replacement for each sample size k from the observed trait values for each trait of each species, then PB(i, k) and TPB(i) were calculated for all CVi,k. Here, CVtrue was estimated by the value of CV1 based on all individuals for each trait and each selected species.
The first dataset contained four traits: mean leaf area (MLA), specific leaf area (SLA), leaf dry mass content (LDMC) and individual height (Height). The dataset included 20,248 individuals (DBH≥1 cm or Height >1.3 m) belonging to 108 tree species in a 5ha subtropical forest plot, Tiantong (hereafter called Tiantong tree data), Zhejiang Province, China (Yan et al., 2018). This dataset represents ITV measurements at a local scale. Of the 108 species, we calculated ITV for seven species which had more than 400 individuals. We selected this abundance threshold because our performance criteria PB(i, k) and TPB(i, k), which depend on the CVtrue, can be estimated within ±0.55% accuracy by any of the above estimators when the sample size is larger than 400. The second trait dataset contained two traits (SLA and LDMC) from four tree species from 72 small (20 m × 20 m) plots in the whole Ningbo region (hereafter called Ningbo tree data), Zhejiang Province, China. It distributed along a 30 km gradient from seaside to inland—and is thus representative of regional scale data. The number of trait measurements for each trait in the Ningbo tree dataset was larger than 170. The third trait dataset contained five traits, head length (HL), interorbital distance (IOD), tympanum diameter (TYD), outer metacarpal tubercle width (OPTW), and tibia width (TW), of a mountain frog species (Feirana quadrana) from the mountain region covering Longmen-Qinling-Daba Mountains (hereafter called Mountain frog data), Central China. A total of 545 individuals were measured for each trait.
We implemented all of the above CV estimators in R functions, and made them available as an R package called “CV” (https://www.github.com/guochunshen/CV). All other performance tests and sample size analyses were performed in R environment (version 3.5.0, R Core Team, 2018).
Results
Analyses of both simulated and empirical trait data showed that CV1, the most commonly used estimator of ITV, consistently underestimated ITV, particularly at small sample sizes (Figures 1 and 2 and S1–S4). Furthermore, among all examined estimators, CV1 had the largest proportional bias at each sample size (left panels in Figures 1 and 2) and total absolute bias across sample sizes (right panels in Figures 1 and 2). The averaged proportional bias of CV1 increased with the extent of extreme values (Figure S5) and exceeded -23% of the true ITV at the sample size of 10 based on Ningbo tree data (black dotted lines in Figure 2C). For particular pairs of species and traits, the underestimations varied largely (Figures S1–S4)—reaching a maximum underestimation of ITV of 48.9% in LDMC of Schima superba in the Ningbo tree data (black dotted lines in Figure S3K).
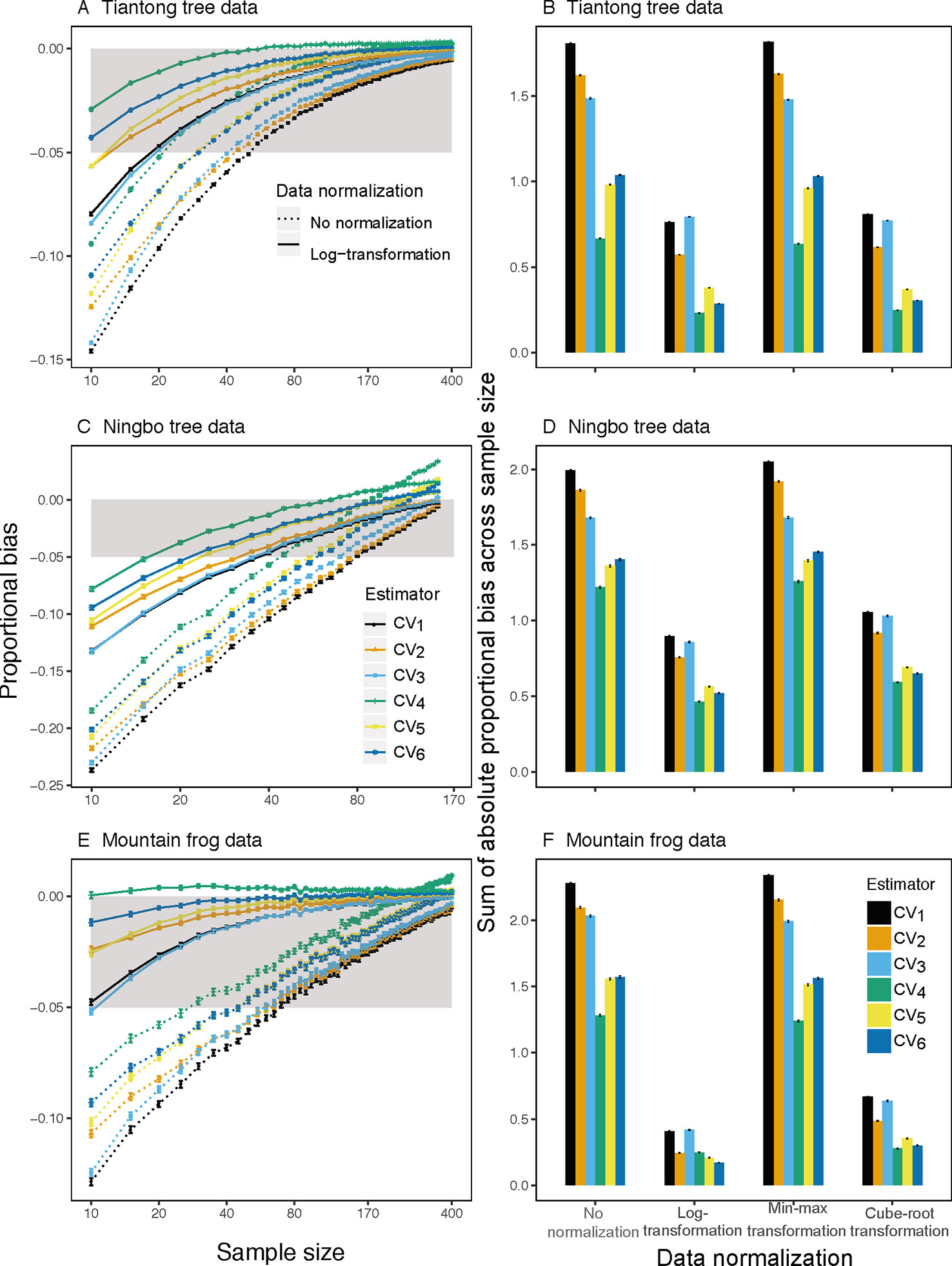
Figure 2 Mean proportion of bias (left panels) on sample size from 10 to 400 for all traits and species based on observed raw (dotted lines) and log-transform (solid lines) trait values and sum of absolute mean proportion of bias across all sample size (right panels) for the ith(i∈{ 1,2,3,4,5,6, }) CV estimator based on observed raw, log-transform, min-max transform, and cube-root transform trait values in three individual-based trait datasets. Gray area is the region in which the absolute mean proportion of bias is less than 0.05.
This underestimation was substantially reduced by substituting CV1 for other estimators and by log-transforming trait data. Among the examined estimators, CV4 had the lowest bias using raw simulated and empirical trait datasets (bluish green dotted line and bar in Figures 1 and 2). The log-transformation further reduced the proportional bias of ITV for all estimators (solid lines in Figures 1–3 and S1–S4), particularly at small sample sizes (<20), and especially for some species-trait pairs (e.g., SLA of Camellia fraternal in Figure 3). Pairwise Wilcoxon tests showed log-transformation significantly reduced mean proportional bias of CV4 in Tiantong tree data (V = 506, P < 0.001), Ningbo tree data (V = 87, P < 0.005), and Mountain frog data (V = 529, P < 0.001). CV4 was again found to be the most accurate estimator with log-transformed data, with one exception: CV6 was the most accurate in the Mountain frog data. The cube-root transformation produced a similar, but relatively weaker reduction of ITV bias, and min-max normalization had no significant effects (right panels in Figures 1 and 2). Overall, CV4 combined with log-transformed trait data was the most robust combination for accurate ITV estimation.
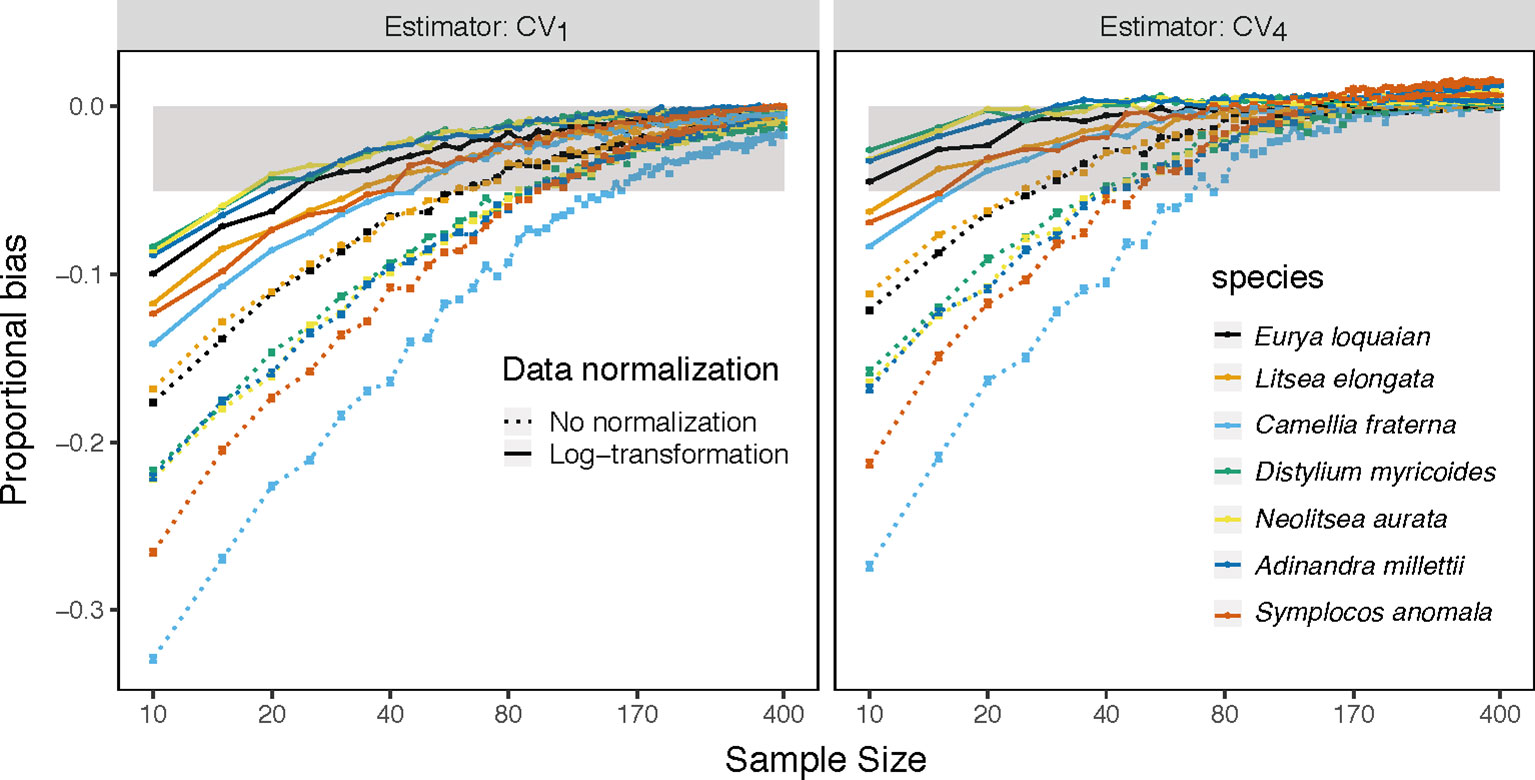
Figure 3 Mean proportion of bias of the CV1 and the best estimator CV4 on sample size k(k∈{10,15,20,…400}) for specific leaf area of each species (colored line) with abundance ≥ 400 based on the raw (dotted line) and log-transform (solid line) trait values in Tiantong tree data. Gray area is the region in which the absolute mean proportion of bias is less than 0.05.
The CV1 and CV4 estimators allowed for the smallest minimum sample sizes to achieve a given level of accuracy (Table 2 and S2). For the CV1 estimator, the minimum sample size varied largely, ranged from 10 to 295, depending on the extent of the max extreme values for each trait (Figure S6). The CV4 estimator could largely reduce the minimum sample sizes required for the same accuracy, but some species-trait pairs (e.g., C. fraternal-MLA) still required more than 100 samples. Finally, combined use of CV4 with log-transformed trait data reduced the minimum sample size need to reach ±5% accuracy to just 20 samples for almost all examined traits and species.
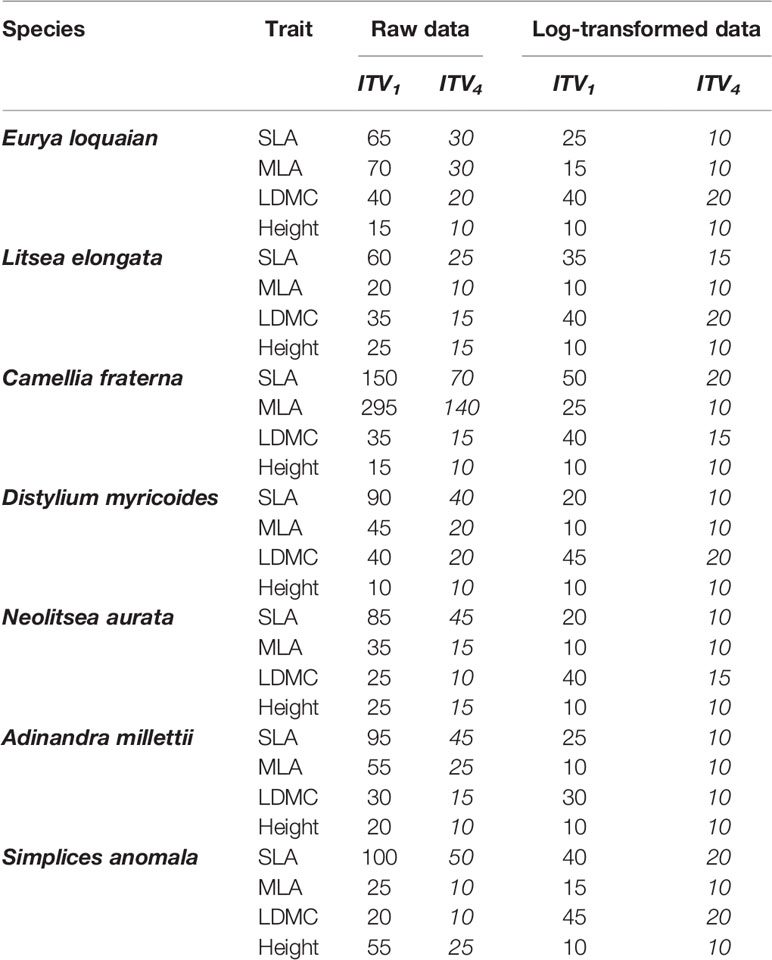
Table 2 Minimum sample sizes of the most commonly used CV estimator CV1 and our best-performed estimator CV4 to reach ±5% accuracy for each trait (SLA, specific leaf area; MLA, mean leaf area; LDMC, leaf dry mass content, Height, individual height) of each species with abundance ≥400 based on the raw and log-transformed Tiantong tree data.
Discussion
By applying performance tests to both simulated and empirical data, we provided the first evidence that ITV quantified by CV1 is often biased under sample sizes that are commonly applied (e.g., <50). When the sample size is around 10, the underestimation of ITV can exceed 48.9%. This pervasive underestimation of ITV by CV1 has largely been ignored in previous studies and has therefore potentially misled subsequent ecological inferences when comparing ITVs among species. The bias of CV1 was different among traits and species and these differences cannot be completely removed by using the same sample sizes, because the source of bias in CV1 includes the skewness and kurtosis of the underlying trait distributions (Breunig, 2001), which generally differ among species and traits (Figures S7–S9). For example, using CV1 and a sample size of 20, Eurya loquaiana appears to have significantly smaller ITV than Symplocos setchuensis; however, using the full empirical data yields exactly the opposite finding (Figure S10A). In this case, after log-transformation, both CV1 and CV4 correctly estimate the relatively magnitudes of ITV of the two species and CV4 is very close to the true ITV (Figure S10B). Future studies of ITV based on CV should be aware of and address these biases. Below, we propose a few strategies to reduce bias based on our comparisons of estimators, data transformations, and samples sizes.
One easily adoptable solution to underestimation is to use a less biased and more robust CV estimator. Our results show that simply replacing the commonly used CV1 for CV4 substantially improved the accuracy of ITV estimation—sometimes by more than 58% (e.g., the average of height ITV of all species in Tiantong tree data). The higher accuracy of CV4 results from its consideration the skewness and kurtosis of the trait distributions. However, CV4 may overestimate ITV when the distribution of raw or log-transformed trait data is close to the normal distribution. CV4 is an approximate form of CV, and therefore can only be truly unbiased when the underlying trait distribution is known exactly. Like CV1, CV2 is derived under the assumption that trait values follow a normal distribution, which has no skewness and kurtosis. The contrasting behaviors of CV4 and CV2 allowed us to construct a simple composite estimator CV6, which was more accurate when the distribution of trait values is close to the normal distribution (Figure S11). In general, we suggest two alternative ITV estimators that apply in different contexts: CV4 will be the least biased when trait data is non-normal—which we believe to be more common—otherwise, CV6 is the best ITV estimator.
In additional to CV estimator selection, we recommend log-transforming raw trait data before using any ITV estimator. This normalization method can substantially improve the accuracy of ITV estimation because the raw trait data often have multiple extreme values that ITV estimators are very sensitive to. The log-transformation places less weight on these extreme large values, which results in a more robust estimation of ITV than the raw trait data. However, there were a few scenarios where log-transformation slightly increased the bias of ITV estimation (e.g., Figures S1C and S3) and additional caution is required when comparing ITVs among species based on log-transformed data. While log-transforming data can help reduce the skewness of data, it is more suited for comparison of ITV on the same log scale. If one feels more comfortable to quantify ITV at the scale of trait measurement or want to compare ITVs with conventional studies based on raw data, log-transformation, or any other data normalization, is not recommended. Instead, researchers should focus their efforts on increasing sample size (e.g., >140) to achieve comparable accuracy. In these cases, ITV can be variously biased, which makings comparisons of ITV challenging.
Next, although labor-intensive, increasing sample size will increase the accuracy of ITV estimation. If CV1 is used, the minimum sample size needed to accurately estimate ITV is often larger than 50; although few conventional studies approach this number. Furthermore, minimum sample sizes required by CV1 vary greatly among traits and species. These large differences likely reflect variation in traits’ distributions and extreme values, which is common in empirical data (Albert et al., 2010b). We showed that the minimum sample size of CV1 depends on the extent of the extreme values, which suggests that the more extreme values present, the more samples may be required for the accurate estimation of ITV (Figure S6). The variation in the minimum sample size of CV1 posits a unique practical challenge to determine the exact minimum sample size for a particular trait of a species. No ‘magic’ minimum sample size will work for all traits from different species. Fortunately, using CV4 and log-transformation simultaneously can reduce sample sizes to about 20 while achieving ±5% accuracy in almost all examined combinations of species and traits. This minimum sample size can be more easily satisfied in the field of functional ecology.
Besides the above mentioned suggestions, there are other ways to improve the estimation of ITV. A smart sampling design other than the complete random sampling used in this study might be helpful. For example, the random sampling scheme may not be effective enough if a large amount of ITV is caused by heterogeneous abiotic environments and the individuals are not proportionally distributed among environmental types. In this situation, a sampling scheme that proportionally covers all types of environments may provide a more efficient representation of the true trait value distribution in the entire population and consequently may improve the accuracy and efficiency ITV estimation (e.g., Albert et al., 2010a; Baraloto et al., 2010 and van de Pol, 2012 but see Burton et al., 2017). Detailed exploration of these different sampling schemes is beyond the scope of this study but worth attention in future studies. Finally, there are other types of methods besides CV (e.g., mixed effect models) that could be used to quantify the relative extent of ITV. For example, if one's aim is to understand the consequences of ITV for community dynamics, directly modeling the trait’s distribution be more fruitful than simply expressing ITV with a single CV value. Detailed comparisons among these methods can be found in Mitchell and Bakker (2014).
In summary, we evaluated the bias in the estimation of ITV using the coefficient of variation with both simulated and empirical trait data. Our results clearly showed that the commonly used estimator CV1 often underestimates ITV, and thus results of ITV studies based on CV1 and small sample sizes should be interpreted with caution. The CV4, or Bao’s CV estimator, combined with log-transformed trait data can largely reduce this bias across many sample sizes, species, and traits. This combination can provide a more accurate tool for comparing trait variability within and among species and studies, facilitating a more robust inferences of the population dynamics (Abbott and Stachowicz, 2016), community assembly (Dibble and Rudolf, 2016; Mitchell et al., 2016) and ecosystem functioning (Barabás and D'Andrea, 2016), as well as facilitate an understanding of global climate change (Moran et al., 2016). More generally, the application of our results may also help reduce bias in any study that uses CV to estimate scientific phenomena, in other fields outside ecology.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Author Contributions
GS designed this study. XW, EY, and JH collected the data. JY and JL analyzed all data with the assistance of GS. JY and YC created the figures. JY and GS wrote this manuscript, and all the co-authors provided some comments and suggestions for the final manuscript.
Funding
This study was supported by the National Key Research and Development Program (2016YFC0503102 to GS) and the National Natural Science Foundation of China (31470487 and 31870404 to GS; 31670438 and 31270475 to EY; 31572290 and 31770568 to JH), as well as the ECNU Multifunctional Platform for Innovation (008).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We are grateful to Fangliang He, Avi Bar Massada, Jian Zhang, Yu Liu, and two anonymous reviewers for their constructive comments and suggestions on the manuscript. We thank Dong He, Min Guo, Qiang Zhong, Meng Kang, Yue Xu, Yilu Xu, Xiaodong Yang, Haixia Huang, Zhihao Zhang, Baowei Sun, Wenji Ma, Qingru Shi, Minshan Xu, Yaotao Zhao, Liuli Zhou, Qingqing Zhang, Arshad Ali, and many other people who made this fantastic trait data available. We would like to thank Ian Gilman at Yale University for his assistance with English language.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2020.00053/full#supplementary-material
References
Abbott, J. M., Stachowicz, J. J. (2016). The relative importance of trait vs. genetic differentiation for the outcome of interactions among plant genotypes. Ecology 97, 84–94. doi: 10.1890/15-0148.1
Agashe, D. (2009). The stabilizing effect of intraspecific genetic variation on population dynamics in novel and ancestral habitats. Am. Nat. 174, 255–267. doi: 10.1086/600085
Albert, C. H., Thuiller, W., Yoccoz, N. G., Douzet, R., Aubert, S., Lavorel, S. (2010a). A multi-trait approach reveals the structure and the relative importance of intra- vs. interspecific variability in plant traits. Funct. Ecol. 24, 1192–1201. doi: 10.1111/j.1365-2435.2010.01727.x
Albert, C. H., Thuiller, W., Yoccoz, N. G., Soudant, A., Boucher, F., Saccone, P., et al. (2010b). Intraspecific functional variability: extent, structure and sources of variation. J. Ecol. 98, 604–613. doi: 10.1111/j.1365-2745.2010.01651.x
Albert, C. H., Grassein, F., Schurr, F. M., Vieilledent, G., Violle, C. (2011). When and how should intraspecific variability be considered in trait-based plant ecology? Perspect. Plant Ecol. Evol. Syst. 13, 217–225. doi: 10.1016/j.ppees.2011.04.003
Archana, V., Rao, K. A. (2011). Improved estimators of coefficient of variation in a finite population. Stat. Transition New Ser. 12, 357–380.
Bao, Y. (2009). Finite-sample moments of the coefficient of variation. Econ. Theory 25, 291–297. doi: 10.1017/S0266466608090555
Barabás, G., D'Andrea, R. (2016). The effect of intraspecific variation and heritability on community pattern and robustness. Ecol. Lett. 19, 977–986. doi: 10.1111/ele.12636
Baraloto, C., Timothy Paine, C. E., Patiño, S., Bonal, D., Hérault, B., Chave, J. (2010). Functional trait variation and sampling strategies in species-rich plant communities. Funct. Ecol. 24, 208–216. doi: 10.1111/j.1365-2435.2009.01600.x
Bastias, C. C., Fortunel, C., Valladares, F., Baraloto, C., Benavides, R., Cornwell, W., et al. (2017). Intraspecific leaf trait variability along a boreal-to-tropical community diversity gradient. PloS One 12, e0172495. doi: 10.1371/journal.pone.0172495
Breunig, R. (2001). An almost unbiased estimator of the coefficient of variation. Econ. Lett. 70, 15–19. doi: 10.1016/S0165-1765(00)00351-7
Brown, J. H. (1984). On the relationship between abundance and distribution of species. Am. Nat. 124, 255–279. doi: 10.1086/284267
Bukowski, A. R., Petermann, J. S. (2014). Intraspecific plant-soil feedback and intraspecific overyielding in Arabidopsis thaliana. Ecol. Evol. 4, 2533–2545. doi: 10.1002/ece3.1077
Burton, J. I., Perakis, S. S., McKenzie, S. C., Lawrence, C. E., Puettmann, K. J. (2017). Intraspecific variability and reaction norms of forest understorey plant species traits. Funct. Ecol. 31, 1881–1893. doi: 10.1111/1365-2435.12898
Clark, J. S. (2010). Individuals and the variation needed for high species diversity in forest trees. Science 327, 1129–1132. doi: 10.1126/science.1183506
Darwin, C. (1859). On the origin of species by means of natural selection, or the preservation of favoured races in the struggle for life. (London, UK: J. Murray). doi: 10.5962/bhl.title.68064
Des, S. R., Post, D. M., Turley, N. E., Bailey, J. K., Hendry, A. P., Kinnison, M. T., et al. (2018). The ecological importance of intraspecific variation. Nat. Ecol. Evol. 2, 57–64. doi: 10.1038/s41559-017-0402-5
Dibble, C. J., Rudolf, V. H. W. (2016). Intraspecific trait variation and colonization sequence alter community assembly and disease epidemics. Oikos 125, 229–236. doi: 10.1111/oik.02373
Griffiths, J. I., Petchey, O. L., Pennekamp, F., Childs, D. Z. (2018). Linking intraspecific trait variation to community abundance dynamics improves ecological predictability by revealing a growth-defence trade-off. Funct. Ecol. 32, 496–508. doi: 10.1111/1365-2435.12997
Hart, S. P., Schreiber, S. J., Levine, J. M. (2016). How variation between individuals affects species coexistence. Ecol. Lett. 19, 825–838. doi: 10.1111/ele.12618
Helsen, K., Acharya, K. P., Brunet, J., Cousins, S. A. O., Decocq, G., Hermy, M., et al. (2017). Biotic and abiotic drivers of intraspecific trait variation within plant populations of three herbaceous plant species along a latitudinal gradient. BMC Ecol. 17, 38. doi: 10.1186/s12898-017-0151-y
Li, Y., Shipley, B., Price, J., Dantas, V., Tamme, R., Westoby, M., et al. (2017). Habitat filtering determines the functional niche occupancy of plant communities worldwide. J. Ecol. 106, 1001–1009. doi: 10.1111/1365-2745.12802
Mitchell, R. M., Bakker, J. D. (2014). Quantifying and comparing intraspecific functional trait variability: a case study with hypochaeris radicata. Funct. Ecol. 28, 258–269. doi: 10.1111/1365-2435.12167
Mitchell, R. M., Bakker, J. D. (2014). Quantifying and comparing intraspecific functional trait variability: a case study with hypochaeris radicata. Funct. Ecol. 28, 258–269. doi: 10.1111/1365-2435.12167
Mitchell, R. M., Wright, J. P., Ames, G. M. (2016). Intraspecific variability improves environmental matching, but does not increase ecological breadth along a wet-to-dry ecotone. Oikos 126, 988–995. doi: 10.1111/oik.04001
Moran, E. V., Hartig, F., Bell, D. M. (2016). Intraspecific trait variation across scales: implications for understanding global change responses. Global Change Biol. 22, 137–150. doi: 10.1111/gcb.13000
R Core Team. (2018). R: A Language and Environment for Statistical Computing (Vienna, Austria: R Foundation for Statistical Computing).
Siefert, A., Ritchie, M. E. (2016). Intraspecific trait variation drives functional responses of old-field plant communities to nutrient enrichment. Oecologia 181, 245–255. doi: 10.1007/s00442-016-3563-z
Siefert, A., Violle, C., Chalmandrier, L., Albert, C. H., Taudiere, A., et al. (2015). A global meta-analysis of the relative extent of intraspecific trait variation in plant communities. Ecol. Lett. 18, 1406–1419. doi: 10.1111/ele.12508
Sokal, R. R., Rohlf, F. J. (1995). Biometry: The principles and practice of statistics in biological research. 3rd ed. (New York, Oxford: Freeman).
Souza, L., Stuble, K. L., Genung, M. A., Classen, A. T. (2017). Plant genotypic variation and intraspecific diversity trump soil nutrient availability to shape old-field structure and function. Funct. Ecol. 31, 965–974. doi: 10.1111/1365-2435.12792
Umaña, M. N., Zhang, C., Cao, M., Lin, L., Swenson, N. G. (2015). Commonness, rarity, and intraspecific variation in traits and performance in tropical tree seedlings. Ecol. Lett. 18, 1329–1337. doi: 10.1111/ele.12527
van de Pol, M. (2012). Quantifying individual variation in reaction norms: how study design affects the accuracy, precision and power of random regression models. Methods Ecol. Evol. 3, 268–280. doi: 10.1111/j.2041-210X.2011.00160.x
Williams, L. J., Paquette, A., Cavender-Bares, J., Messier, C., Reich, P. B. (2017). Spatial complementarity in tree crowns explains overyielding in species mixtures. Nat. Ecol. Evol. 1, 63. doi: 10.1038/s41559-016-0063
Keywords: individual variation, trait variability, coefficient of variation, CV estimator, bias, Tiantong
Citation: Yang J, Lu J, Chen Y, Yan E, Hu J, Wang X and Shen G (2020) Large Underestimation of Intraspecific Trait Variation and Its Improvements. Front. Plant Sci. 11:53. doi: 10.3389/fpls.2020.00053
Received: 17 July 2019; Accepted: 15 January 2020;
Published: 13 February 2020.
Edited by:
Wolfram Weckwerth, University of Vienna, AustriaReviewed by:
Santiago Ramírez Barahona, National Autonomous University of Mexico, MexicoMatthew David Herron, Georgia Institute of Technology, United States
Copyright © 2020 Yang, Lu, Chen, Yan, Hu, Wang and Shen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guochun Shen, gcshen@des.ecnu.edu.cn