Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model

National Key Laboratory of Science and Technology on Multi-spectral Information Processing, School of Automation, Huazhong University of Science and Technology, Wuhan 430074, China
*
Authors to whom correspondence should be addressed.
Sensors 2018, 18(1), 128; https://doi.org/10.3390/s18010128
Submission received: 30 October 2017
/
Revised: 28 December 2017
/
Accepted: 2 January 2018
/
Published: 5 January 2018
(This article belongs to the Section Physical Sensors)
Abstract
:Extended from superpixel segmentation by adding an additional constraint on temporal consistency, supervoxel segmentation is to partition video frames into atomic segments. In this work, we propose a novel scheme for supervoxel segmentation to address the problem of new and moving objects, where the segmentation is performed on every two consecutive frames and thus each internal frame has two valid superpixel segmentations. This scheme provides coarse-grained parallel ability, and subsequent algorithms can validate their result using two segmentations that will further improve robustness. To implement this scheme, a voxel-related Gaussian mixture model (GMM) is proposed, in which each supervoxel is assumed to be distributed in a local region and represented by two Gaussian distributions that share the same color parameters to capture temporal consistency. Our algorithm has a lower complexity with respect to frame size than the traditional GMM. According to our experiments, it also outperforms the state-of-the-art in accuracy.
1. Introduction
Superpixel segmentation is to partition a still image into atomic segments of similar size and adhering to object boundaries, namely superpixels [1,2,3,4]. In recent decades, superpixel segmentation has been found to be a very useful preprocessing step in many computer vision tasks (e.g., object detection [5,6,7], image segmentation [8,9,10], visual saliency [11], and noise estimation [12]). This is mainly because superpixels improve the computational efficiency and robustness of subsequent applications by reducing the number of inputs and removing a large amount of redundant information.
Because of the effectiveness of superpixel segmentation, the idea of partitioning data points into homogeneous atomic clusters has been extended into video analysis by adding a constraint on temporal consistency [13,14]. The new atomic cluster in video is called the supervoxel, as the video analog to the superpixel in a still image [15]. In addition to the constraints inherited from superpixel segmentation (i.e., adhering to object boundaries and having similar size), the new temporal constraint—namely spatiotemporal coherence—requires that a supervoxel belong to the same object over time. Superpixel and supervoxel are used interchangeably in the following text because a supervoxel in a single frame is a superpixel. Existing works solve the supervoxel problem by either stacking video frames together as 3D volumetric data and performing segmentation by treating the time axis as an additional spatial dimension (e.g., [1,16]), or tracking or propagating the initial superpixel segmentation from the first frame through inferring temporal correspondence in successive frames (e.g., [17,18,19]). Methods falling into the first category cluster video pixels in 3D Euclidean space with color information added to each point. This strategy may result in supervoxels only preserving temporal consistency in very few neighboring frames. When more frames are considered, the same object in the video can be easily separated into different supervoxels, even if the video is completely stacked by the same single still image. These kinds of methods seem to be more suitable for real 3D volumetric data (e.g., 3D electron microscope (EM) images), and not appropriate for video.
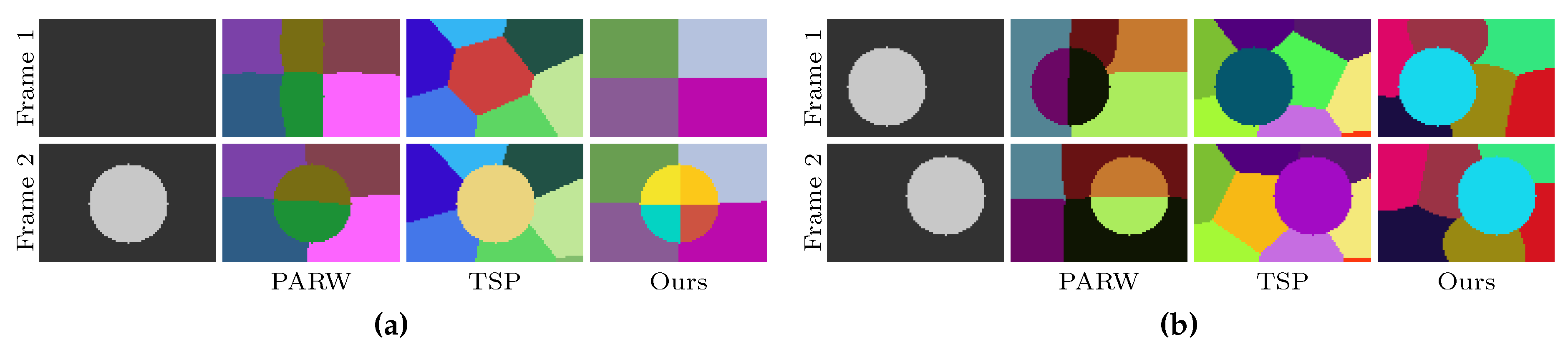
More methods explore the second strategy to improve the temporal consistency of supervoxels. Generally, those methods extract the superpixels of the current frame by using the immutable segmentation of the previous frames [13,17,20]. For instance, the method using partially absorbing random walks (PARW) [17] initializes superpixels for the current frame using the seeds of the previous frame and generates new superpixels based on the current frame and the next frame. Because the segmentations of the previous frames are immutable, the seeds that were used to initialize superpixels of the current frame may change to a different object due to occlusions, and thus the temporal consistency is easily lost (Figure 1a illustrates this problem). As shown in Figure 1a, temporal superpixels (TSP) [20] is able to detect “dead” and “new” superpixels to deal with object occlusion. However, their model overacts when dealing with moving objects, as shown in Figure 1b. Moreover, most of the existing supervoxel algorithms rely on optical flows [18,19,21], which strongly influence their temporal consistency and execution speed.
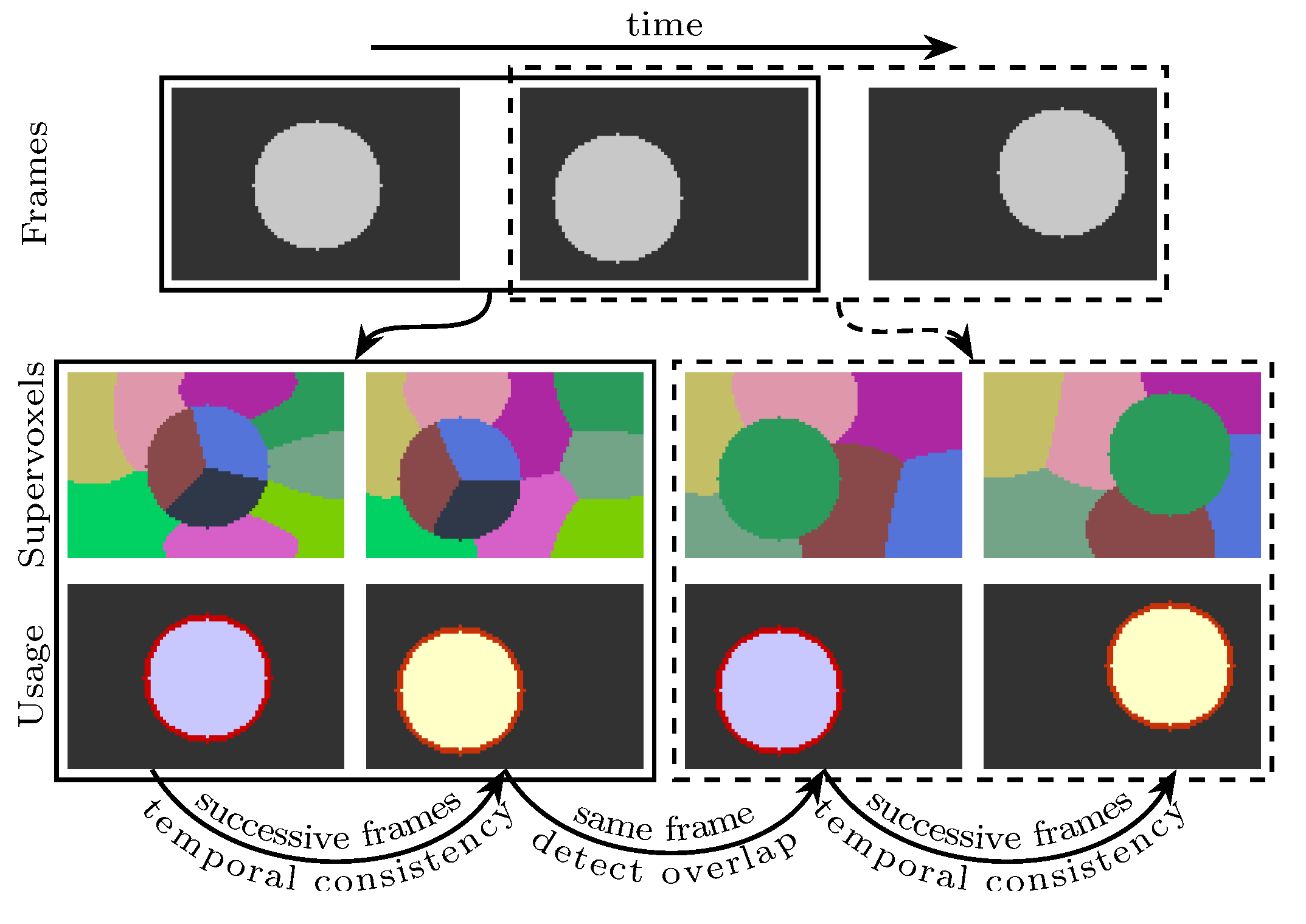
Aiming to improve the temporal consistency of supervoxel segmentation when video is with object occlusion and moving objects, we propose an alternative scheme that takes only two adjacent frames into account at a time and produces two valid segmentations for each internal frame. Except for the original colors and spatial locations, our method does not rely on any precomputed information (e.g. optical flows). This scheme has two major benefits: (a) it provides a coarse-grained parallelism that every two frames can be segmented in parallel; (b) each internal frame having two segmentations gives the subsequent applications an opportunity to validate their results. A possible usage of our supervoxels is depicted in Figure 2, where the propagation of a segmentation is not performed at the superpixel level but at the object level.
The traditional Gaussian mixture model (GMM)—a weighted sum of Gaussian functions—has been widely applied to the problem of classification [22,23]. However, it cannot be directly applied to supervoxel segmentation because its computational complexity is relatively high and it does not encode the constraint on segment size. GMM has been explored for superpixel segmentation and achieved good segmentation accuracy in our previous work [24]; however, temporal consistency was not considered. In this work, we extend the model of [24] to supervoxel segmentation and propose a voxel-related GMM to tackle temporal consistency. Inherited from [24], we use constant weights and subsets of all the Gaussian functions in the sums to ensure that the produced segments have similar sizes and that the algorithm has linear complexity. In our new model, the size of the subsets is controllable so that we can tune it to track objects with different moving speed. For instance, a large size is suitable for videos containing fast-moving objects (see Section 3.4 for more details). Each supervoxel is composed of two superpixels on two consecutive frames, and each superpixel is represented by a Gaussian distribution. To ensure temporal consistency, we use the same color parameters (i.e., color mean vector and color covariance matrix) for the two distributions of each supervoxel. This is mainly because the same object in two consecutive frames tends to be similar in color. Experiments conducted on a well-known dataset show that the proposed algorithm is superior to the state-of-the-art in terms of accuracy.
2. Related Works
Using superpixels as basic elements for image analysis and processing was first introduced by Ren and Malik [25]. After the algorithms proposed in [1,16,26], the following works of extracting superpixels for video data began to take temporal consistency into account. In this section, we will review some representative algorithms that are related to supervoxel segmentation.
The hierarchical graph-based method (GBH) [26] constructs a 3D graph using all the video frames and applies Felzenszwalb and Huttenlocher’s algorithm [27] to iteratively merge voxels using a hierarchical scheme. Instead of building a regular grid graph base on a 26-neighborhood in 3D spatial temporal space, the edges between frames are built in such a way that each voxel is connected to its nine neighbors along the backward flow vector. The flow vectors are also used in the clustering process. This method uses dense optical flow to ensure temporal consistency. However, errors from the precomputed flows may shift to the segmentation process. Additionally, GBH cannot generate supervoxels with similar size, and the number of supervoxels cannot be directly controlled. Since GBH requires all frames to be loaded into memory (in which case it may fail for a longer video), Ref. [28] gives an implementation of GBH to make it have a streaming capability by using a Markov assumption.
Simple linear iterative clustering (SLIC) [1] uses a modified k-means to group pixels based on their spatial location in a still image. In each iteration of SLIC, the search space of the current superpixel is limited to a square region whose center is the spatial center of the current superpixel and whose size is proportional to the desired size of each superpixel. To extend the modified k-means to video data, voxels in frames are seen as points in 3D Euclidean space, and thus the search space becomes a cube. Seeds are regularly distributed among the fake 3D volumetric data, and as a result supervoxels are temporally consistent only over a short range of frames. In SLIC, small connected regions are merged into neighboring supervoxels in a 3D 10-neighborhood. However, a moving object captured in different frames may not be connected in the 10-neighborhood. Therefore, the merging step may cause a negative effect on the segmentation accuracy. Similar to SLIC, the method besed on graph cuts (GC) [16] also stacks all frames together as a fake 3D volume. GC extracts supervoxels by partitioning graphs in an energy minimization framework optimized using graph cuts. However, GC cannot guarantee temporal consistency for a long range of frames.
Spatiotemporal closure (SC) [18] starts by extracting superpixels in the first frame using the original method of TurboPixels [3]. The seeds for the superpixel segmentation of the next frame are projected along the weighted flow vectors from the segmented seeds of the current frame. This method also relies on precomputed optical flow and is not self-contained. An incorrect flow vector may easily produce a supervoxel that covers multiple objects. Following works like Ref. [13], PARW [17] use a similar method to move seeds from the superpixel segmentation of the current frame to the next adjacent frame. Although TSP [20] does not move seeds with the aid of optical flow, seeds are still moved from an immutable superpixel segmentation, and the seeds may be further evolved to a new object. Superpixels Extracted via Energy-Driven Sampling (SEEDS) [29,30] was first designed for superpixel extraction, and is extended to video data in video SEEDS (vSEEDS)[19]. Instead of moving superpixel representatives from previous segmentations, vSEEDS propagates the rough block-level segmentation of each frame into the next frame. However, vSEEDS still shares the same drawback with the seeds moving methods when dealing with new objects.
Overall, existing supervoxel algorithms generally require motion information to aid the segmentation. However, this kind of information is not originally equipped with the frames, and needs to be computed by additional algorithms. The error in motion vectors may result in erroneous results in supervoxels. Algorithms that evolve previous superpixel segmentation to new frames usually make the previous segmentation immutable. Because the previous labels may shift to a new object, these methods often fail to handle new objects or moving objects.
3. The Method
In the proposed method, the supervoxel problem is simplified as supervoxel segmentation on two adjacent frames (see Figure 2 for an illustration). Each voxel is represented by a five-dimensional vector, in which the time property is not involved. Inspired by Ref. [13], the time property of each voxel is modeled in an implicit fashion such that data points are organized in subspaces: one color subspace and two spatial subspaces (each frame has one spatial subspace). Each supervoxel is composed of two superpixels, each of which is associated to a Gaussian distribution with unknown parameters. To estimate the parameters, voxels are assumed to be observed from a mixture of Gaussian distributions. Based on maximum likelihood estimation, the unknown parameters are estimated using the expectation–maximization (EM) method. Once the values of the parameters are obtained, each voxel’s supervoxel label is determined to be the one that has the maximum posterior probability.
3.1. Problem Formulation
For a given sequence of frames, we use to denote pixel i in frame t, with and , where is the pixel index set and T is the frame set. The symbol denotes the number of elements in a given set; e.g., is the number of pixels in each frame, and is the number of frames. The width and height of the frames are denoted by W and H, respectively. Hence, we have .
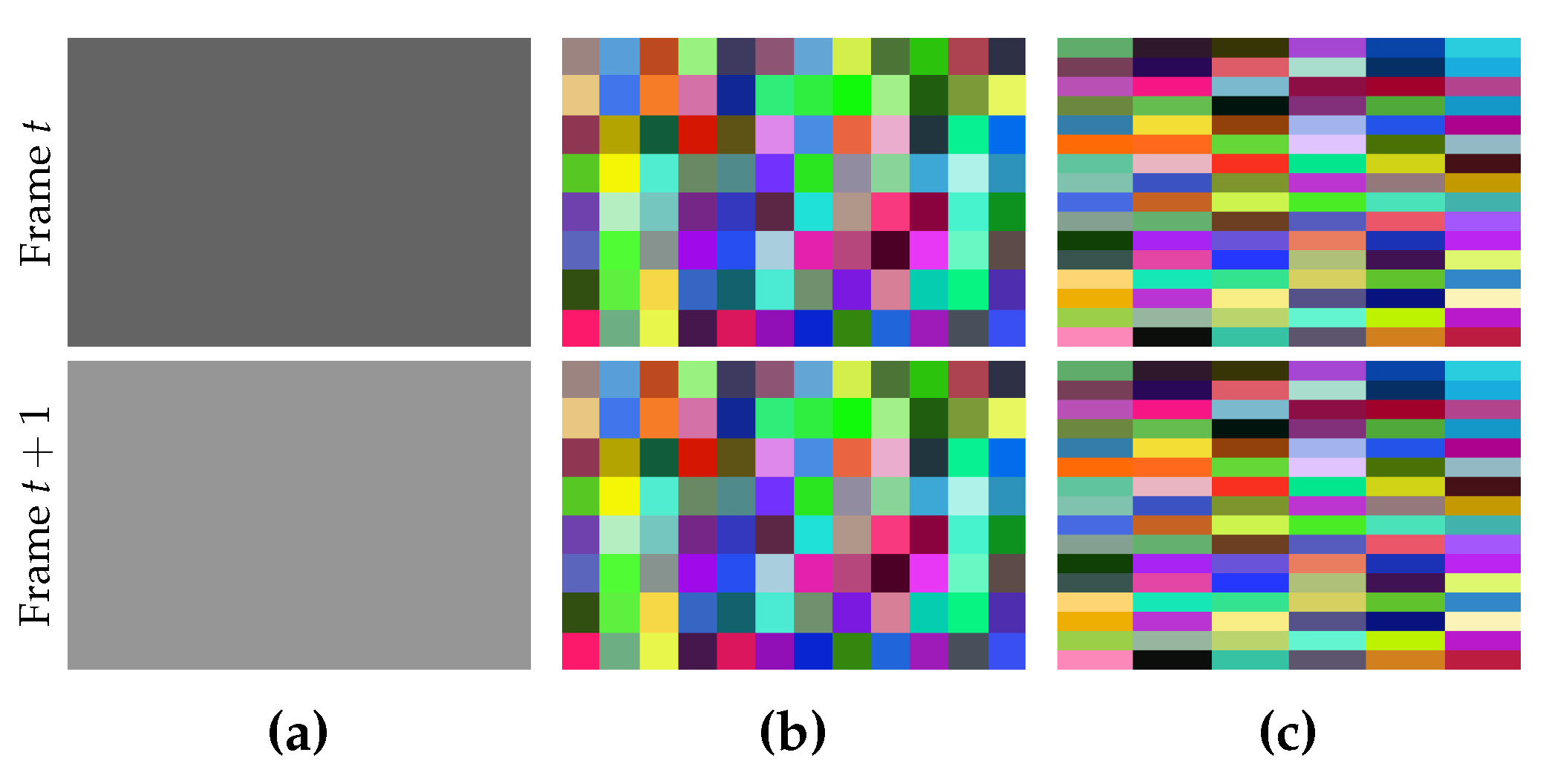
The desired size of each superpixel in a given frame is specified by , where and are the number of pixels along width and height, respectively. Usually, the values of and are given by users. If we use values with a large difference, the shape of the generated superpixels in each frame will tend to be a narrow rectangle (see Figure 3). Although people can assign different values to them, it is encouraged to assign the same value, or at least two different values with a very small difference, unless the narrow shape is useful for a special purpose.
Supervoxel segmentation is to assign each voxel a unique label. Voxels with the same label form a supervoxel. All the possible supervoxel labels form a supervoxel set , where is the number of supervoxels, which is computed in Equation (1):
where and are the desired numbers of superpixels along width and height for a single frame. For simplicity, we assume and .
In this work, the supervoxel segmentation procedure is performed on every two frames. Therefore, a supervoxel is only valid on two successive frames. For instance, if some voxels in frame t and frame share the same supervoxel label, they are a subset of the same supervoxel. However, if the voxels are in frame t and frame , they are not in the same supervoxel. In order to provide cues for some subsequent applications (e.g., object tracking), frame t—where and —will be used two times. In the first time, the segmentation is performed on frame and frame t. In the second time, the same procedure of segmentation is performed on frames t and . By doing this, frame t will have two valid superpixel segmentations. The detected regions in frame t can be propagated by finding the overlapping superpixels in the second segmentation (see Figure 2 for an illustration). Because the same methods are used to segment any two frames, the supervoxel problem becomes finding K supervoxels for frame t and such that the generated supervoxels are similar in size, adhere to object boundaries well, and are temporally consistent. Therefore, only frame t and frame will be considered in Section 3.2.
3.2. The Model
To distinguish variables between two frames, a symbol with a hat at its top indicates that the symbol is related to frame . Each voxel in frame t is represented by a five-dimensional vector including spatial location and three CIELAB color components—lightness and two color components and . This can be expressed by
in which the superscript T indicates vector transpose. Similarly, voxel i in frame is represented using
For two given frames t and , voxels are assumed to be distributed according to mixtures of Gaussian distributions in which each Gaussian distribution corresponds to a superpixel. Gaussian function is defined in Equation (4), where the semicolon is used to separate variables and parameters:
in which z is a D-dimensional column vector, and are mean vector and covariance matrix, respectively.
Generally, if voxels in different frames have similar colors and have small spatial distances, they generally belong to the same object. This is particularly true in the videos with moving objects. To incorporate this notion into our model, we use different parameters for spatial information but the same parameters for color information for the same supervoxel in the definition of voxel density functions and , as shown in Equation (5). This is the key point to ensure temporal consistency:
in which
where and are spatial mean vectors and spatial covariance matrices for frame t with . Their parallel notations and are for frame . The color mean vectors and color covariance matrices are for both frame t and frame . Supervoxel k can be characterized by the parameters , , , , , and , and thus each supervoxel corresponds to two Gaussian distributions. Accounting for the locality of supervoxels, in Equation (5) is a subset of , and its elements are related to the spatial location of voxel i. The definition of will be discussed later. Instead of defining as a variable just like existing Gaussian mixture models, is defined as a constant here to make the generated supervoxels similar in size.
Once two successive frames t and are given, parameters in the Gaussian densities can be inferred and the label of each voxel, for frame t and for frame , will be determined by the following equations:
in which is the probability of assigning voxel i in frame t to supervoxel k given the observation . has a similar meaning. By applying Bayes rule, the posterior probabilities in Equation (7) can be expressed by
Based on Equations (7) and (8), and can be computed by the equivalent equations, as shown below:
3.3. Estimating Parameters of Gaussian Distributions
Given two frames t and , we use the method of maximum likelihood to estimate the unknown parameters in the Gaussian distributions. Since the proposed density functions for voxels may be not identical because the elements in may be different for different (see Section 3.4 for details), updating formulas for traditional GMM cannot be simply copied to our new model. Therefore, we will derive the updating formulas for the proposed model in this section by applying the classical expectation–maximization (EM) method to iteratively improve the log-likelihood.
As the voxels in frames t and are assumed to be distributed independently, the log-likelihood for the two frames can be written out as follows:
where is a vector of all the unknown parameters composed of , , , , , and with . For each supervoxel k, and . Because the number of elements in supervoxel set is constant (see Section 3.4), the value of the parameter that maximizes is equal to the value that maximizes the following function :
It is difficult to find the optimal value for by maximizing directly. We insert new variables and into Equation (12) such that
Then, Equation (12) will become Equation (14). By applying Jensen’s inequality, the EM method is to alternatively find satisfying the equality of the inequality in Equation (15) with parameters in being known (expectation step or E-step), and find parameters in that maximize which is defined in Equation (15) using the obtained R (maximization step or M-step):
E-step: According to the theory of Jensen’s inequality, equality holds if and only if
are constant. With the constraints in Equation (13), formulas to update R can be derived by eliminating the temporal variables and in Equation (16), as shown below:
where is defined in Section 3.4.
M-step: To find the parameters that maximize , we first get the partial derivatives of with respect to different components of , as shown in Equations (18)–(22), and then set them to zero to get the optimal , which is shown in Equations (24)–(27):
where and are spatial vectors of voxel i in frame t and , respectively. Similarly, and are color vectors. For each supervoxel k, is a voxel set that supervoxel k may cover, and is deduced from as shown in Equation (23):
Usually, the EM method starts by feeding it with a guess of the parameters in . Then, R and will be alternatively updated using the formulas mentioned in E-step and M-step. However, there is a risk that the covariance matrices may become singular and we may fail to obtain their inverse matrices. For example, when the voxels in have the same constant color, during the iteration of EM will become zero matrix, which is obviously singular. To avoid this trouble, one can perturb each and each with a small random vector before the EM iterations. This trick may succeed in most cases, but it may fail when an object in a frame is very narrow (e.g., a straight line), in which case certain covariance matrices or may become singular. In order to prevent the covariance matrices from being singular, we first obtain their eigenvalues and impose a lower bound to the eigenvalues to reproduce the covariance matrices. When an eigenvalue is less than the specified lower bound, we assign the eigenvalue to that lower bound. We use and to denote the lower bound of spatial eigenvalues and color eigenvalues, respectively. Experimentally, we have found that and is appropriate to outperform the state-of-the-art algorithms. We will use this setting for the remaining text.
In theory, the iteration of the EM method will not stop until the parameters in converge. However, EM needs hundreds of iterations to reach the condition of convergence, resulting in a low computational efficiency. In practice, aiming to reduce run-time, we use a fixed number of iterations , which is sufficient in practice for generating supervoxels with state-of-the-art accuracy.
3.4. Defining and Initializing
The definition of supervoxel subsets of will be discussed in this section using mainly the notations mentioned in Section 3.1. After the value of and are assigned, we define rectangle regions called anchor regions, with each anchor region corresponding to a supervoxel. As illustrated in Figure 4, for each frame, an anchor region contains voxels and all the anchor regions are regularly placed on every frame. For a given supervoxel k, all voxels in its anchor region are assigned an anchor label . Then, is defined using the anchor label of voxel i using the following equations:
where and are parameters used to control the number of supervoxels from which each voxel i may be generated. Clearly, at least one of the two parameters must be greater than or equal to 1.
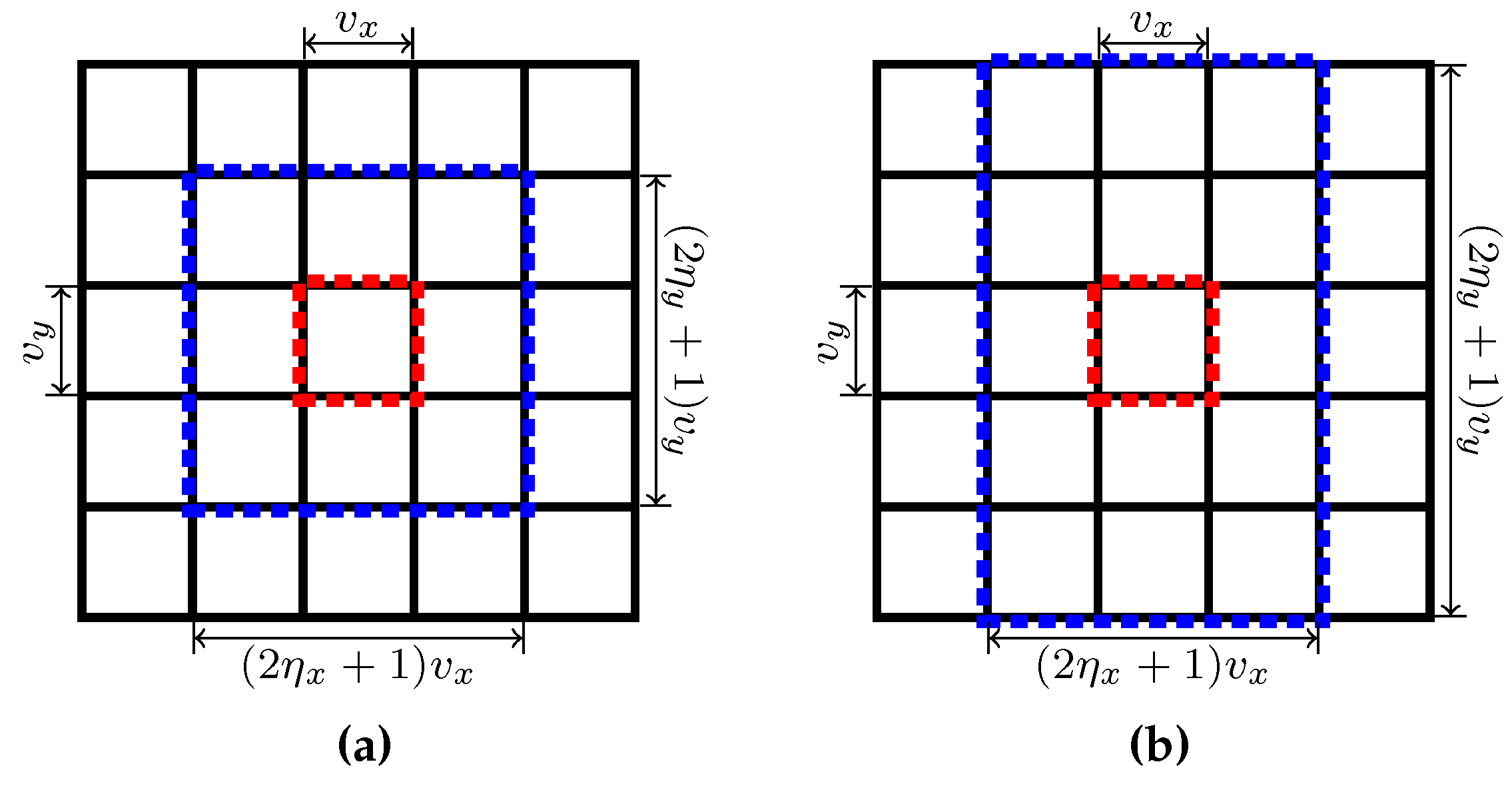
Recall the definition of in Equation (23) of Section 3.3. Elements of are in turn determined by . The voxel set is called the k-th supervoxel’s overlap region, into which voxels in supervoxel k may spread. With the help of Figure 4, it is easy to conclude that an overlap region of a supervoxel k is the region whose center is the anchor region of the supervoxel k and whose width and height can be divided evenly by and respectively, and can be expressed by and using and . There are some exceptions, however. When an anchor region k is at the boundary of a frame, the size of may be less than , but is at least , which is the case in which the anchor region is at one of the four corners of the frame. This conclusion can be used to deduce the computational complexity of our algorithm. As discussed in Section 3.5, the computational complexity can be affected by and . A large value for will increase the run-time of the algorithm. Meanwhile, a large value for indicates that a supervoxel has a large overlap region, which may result in a better performance in temporal consistency. By default, we use for our experiments.
In our model, a Gaussian distribution represents a superpixel in a single frame, and two Gaussian distributions with the same color parameters (color mean vector and color covariance matrix) but with different spatial parameters represent a single supervoxel. As we expect that the generated superpixels are regularly distributed on each frame, it is straightforward to initialize and using the center of the k-th anchor region. Since a color mean vector varies according to the color information of two frames (see Equation (26)) during the EM iterations, the is initialized by the mean color of the two voxels at the center of the k-th anchor region of each frame.
For each supervoxel k, the corresponding covariance matrices serve as normalizers for the squares of the Euclidean distances (refer to Equations (4) and (9)). To initialize each of the covariance matrices, the idea is to assign their diagonals with the same value, which can be interpreted as a distance within which two voxels tend to be in the same supervoxel. We have found that it is sufficient to initialize color covariance matrices with a color distance (see Equation (30)) and a small perturbation for affects the result less. As we hope each superpixel for a single frame will have the same size , the spatial covariance matrices can be initialized using Equation (30):
3.5. Computational Complexity
With the discussion above, for any two successive frames, the proposed algorithm can be summarized in Algorithm 1. The proposed algorithm is composed of three major procedures, initializing (line 1 to line 3), updating R (line 5 to line 9), and updating (line 10 to line 13). It is obvious that the initialization of needs a computational cost of , where K is the number of desired supervoxels in two frames and is originally defined in Equation (1).
| Algorithm 1 The proposed supervoxel algorithm. |
| Input: and , two successive frames. Output: and , . 1: for all do 2: Initialize , , , , , (refer to Section 3.4). 3: end for 4: for to M do {refer to Section 3.3 for the value of M} 5: for all do 6: for all do {refer to Section 3.4 for } 7: Update and using Equation (17). 8: end for 9: end for 10: for all do 11: Update , , and using Equations (24)–(26). 12: Update , and using Equations (24)–(27). 13: end for 14: end for 15: for all do 16: and are determined by Equation (9). 17: end for |
According to Equations (28) and (29), the number of elements in satisfies the following inequality:
For each voxel i, updating or , needs time . For all the elements in R, we therefore have a computational complexity . Based on Equations (24)–(27), for a given supervoxel k, updating the parameters in or needs a time of . By the conclusions about the size of in Section 3.4, we know that
Therefore, the computational complexity for updating is
Because and we use constant values for and , the computational complexity of our algorithm is .
When the input video has more than two frames, every internal frame will have two segmentation results: one generated with its previous frame and another generated with its next frame (refer to Figure 2 for a visual illustration). For the entire video sequence, the complexity is , where is the number of frames in the input video and has been mentioned in Section 3.1.
4. Experiments
Our method has been designed to produce supervoxels of similar size. To evaluate the performance of our algorithm, it is reasonable to compare the proposed method with algorithms that are also designed to generate supervoxels of similar size. We compared our method with four of these kinds of algorithms, including video SLIC [1] (vSLIC), PARW [17], vSEEDS [19], and TSP [20], whose source codes are publicly available at their respective research websites. We used the default parameters provided by their authors for all the compared methods. Comparisons of some early methods that oversegment video data without considering the property of similar size can be found in the work of [15].
4.1. Quantitative Comparisons
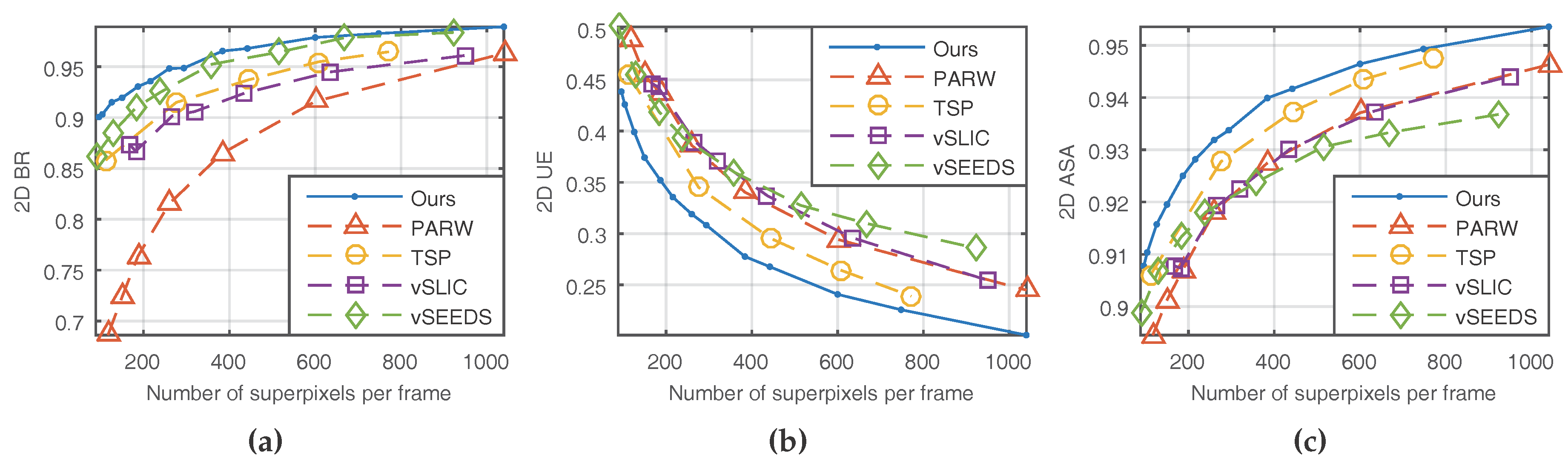
We conducted experiments on the Chen dataset [31] and adopted five metrics to evaluate the quality of the supervoxels generated by different algorithms. This dataset contains eight video sequences, and every frame has a ground truth label. Each metric is compared as a function of the average number of superpixels per frame.
Three of the five metrics are borrowed from still image segmentation, and they are 2D boundary recall (2D BR), 2D under-segmentation error (2D UE), and 2D achievable segmentation accuracy (2D ASA). For a single frame with ground truth labels, 2D BR measures the proportion of ground truth boundaries that fall within two pixels of the superpixel boundaries [3]. As shown in Figure 5a, our method and vSEEDS [19] worked equally well in terms of boundary recall when a relatively large number of superpixels are generated. However, the superiority of our method becomes obvious with the decrease of the number of superpixels.
2D UE, shown in Figure 5b, is another important measure of boundary adherence. For a single frame, given a region from the ground truth segmentation and the set of superpixels required to cover it, , where denotes an empty set, 2D UE measures how many pixels from are not in the region . Given that is the number of elements in a given set, G is the set of ground truth segments, and M is the minimum number of pixels in overlapping , 2D UE can be expressed as
It is generally accepted to set M to five percent of to account for ambiguities in the ground truth segmentations. Superpixels that do not tightly adhere to the ground truth indicate high 2D UE. Clearly, our method had the minimum under-segmentation error, as shown in Figure 5b.
If we assign every superpixel with the label of a ground truth segment that covers the greatest number of pixels of the corresponding superpixel, 2D ASA measures how much segmentation accuracy we can achieve or how many pixels are correctly segmented, as shown in Equation (35):
Superpixels with high segmentation accuracy will result in a high value of 2D ASA. As shown in Figure 5, our method achieved the best 2D ASA.
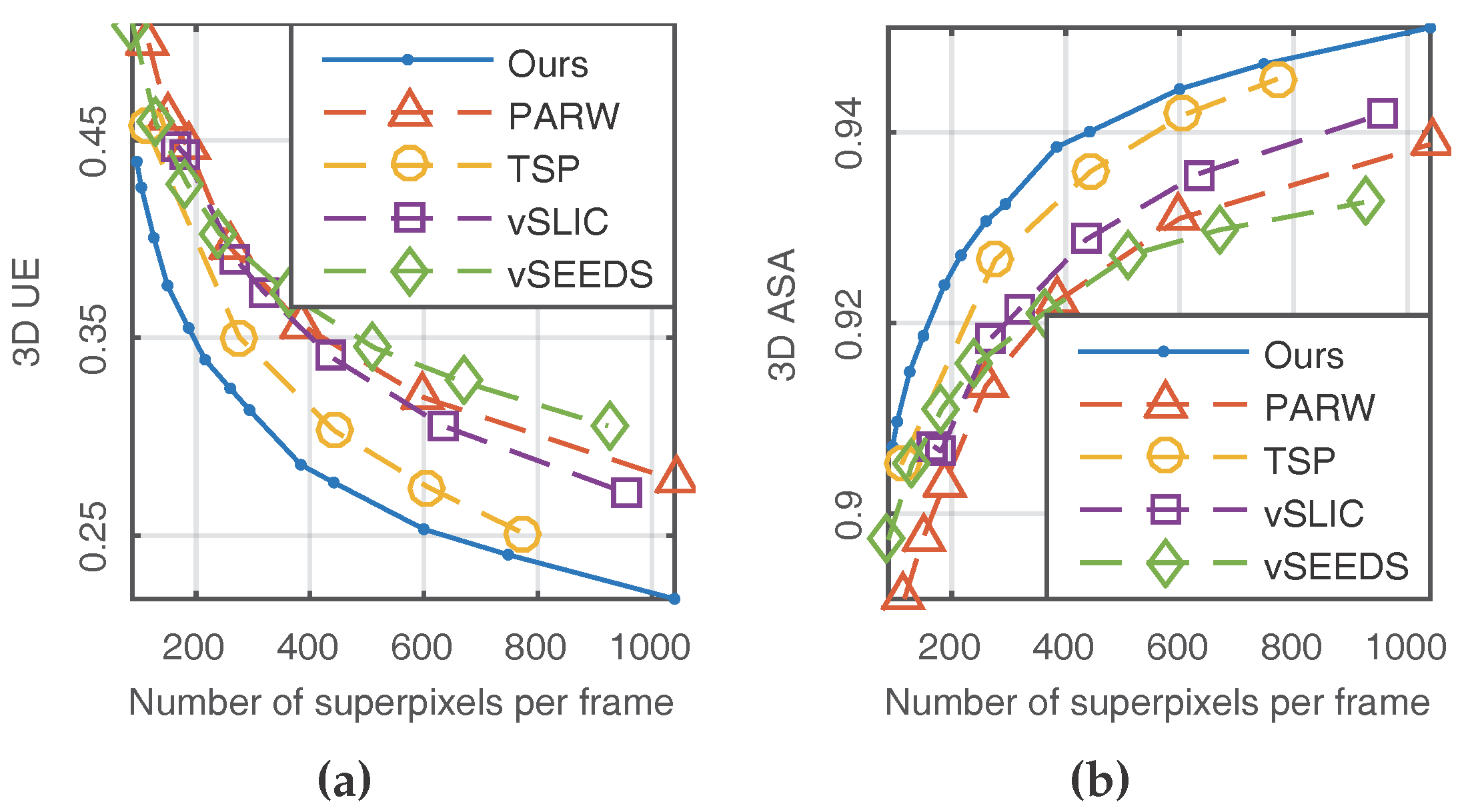
The other two metrics—namely 3D UE and 3D ASA—were used to evaluate temporal consistency by performing the formulas of 2D UE and 2D ASA on every two consecutive frames. Similarly, low 3D UE and high 3D ASA indicate better performance. As shown in Figure 6, our method presented the best temporal consistency.
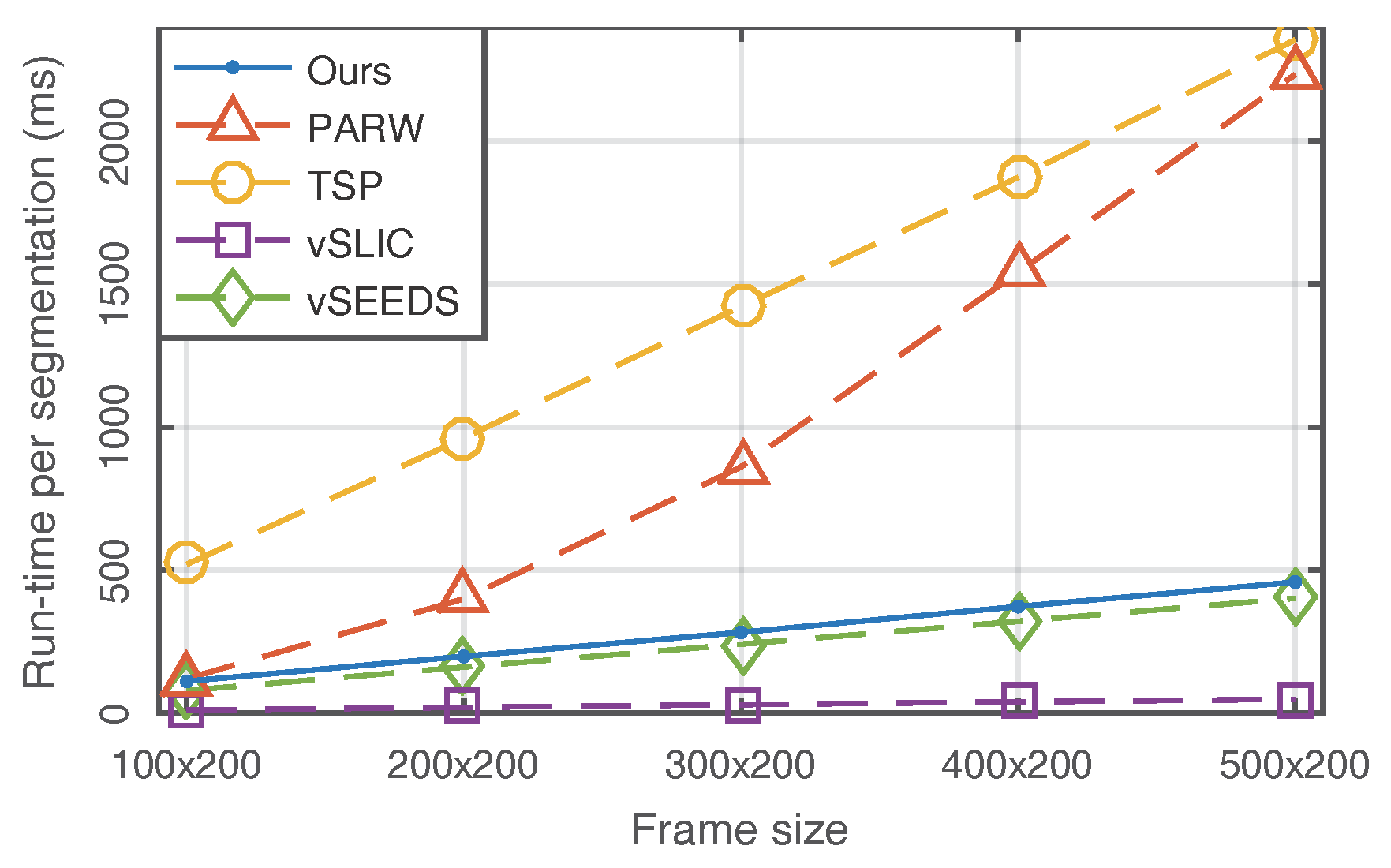
To compare computational efficiency, we test the selected algorithms on a 4-core Intel CPU at 3.3 GHz. As shown in Figure 7, although our algorithm did not show the best performance in terms of run-time, it is still worth noting that we achieved better results than PARW and TSP and had extremely similar performance to vSEEDS. vSLIC presented the best run-time. However, vSLIC is not a real supervoxel algorithm because it treats video as a fake 3D volume and temporal consistency is not real considered in vSLIC. In addition, Figure 7 experimentally confirms that our method is of linear complexity with respect to frame size.
4.2. Qualitative Comparisons
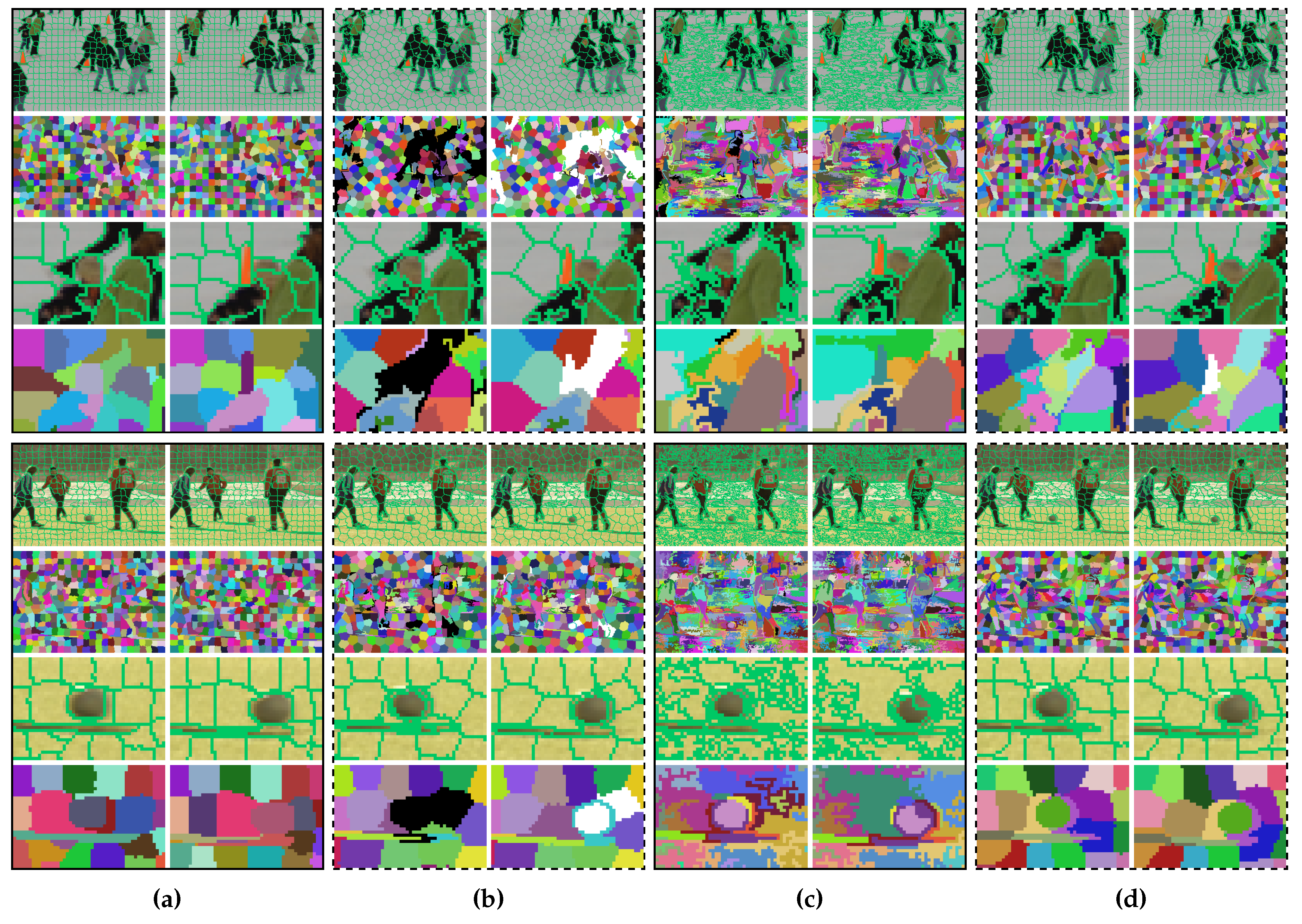
As displayed in Figure 8, we selected four frames from the Chen dataset to compare the segmentation results of four algorithms. Note that vSLIC is not included because it does not consider temporal consistency for real and cannot segment videos with very few frames [1] (e.g., two frames). Our algorithm correctly assigned a new label for the new appearing object, as shown in the fourth row of Figure 8d. Although TSP also correctly detected the new object, this algorithm is easy to overact (certain moving objects are assigned with new labels in Figure 8b). If an object has similar colors in two different frames, our method is able to track it. For instance, most of the supervoxels of our method preserved temporal consistency, as shown in the third last row of Figure 8d, in which the three people and the soccer ball of moving in different directions are similar in color between the two frames. vSEEDS succeeded in segmenting the moving soccer ball, as shown in Figure 8c. However, supervoxels of vSEEDS tend to be considerably dissimilar in size.
Although supervoxel algorithms are not real visual tracking algorithms, supervoxels may be useful in visual tracking. For example, instead of tracking a rectangle window, a tracking algorithm can track the superpixels to either save computing time or improve robustness. In this case, the temporal consistency that supervoxel algorithms attempt to capture becomes an important property that can boost the performance of such tracking algorithms. To compare the performance in terms of temporal consistency when many frames are involved, we manually select some superpixels that cover the same region in one frame and track them using temporal consistency. As shown in Figure 9, Figure 10 and Figure 11, our method presented the best results in tracking the three different kinds of objects.
5. Conclusions
A temporal superpixel algorithm was developed based on our novel voxel-related Gaussian mixture model (GMM). Instead of producing immutable superpixels for each frame, we proposed a new scheme for supervoxel segmentation. In this scheme, every two adjacent frames are independently segmented into superpixels and so that every internal frame has two valid superpixel segmentations, which provides our algorithm with a coarse-grained parallel ability and allows subsequent applications to adjust their results on each internal frame to further improve robustness.
In the voxel-related GMM, a supervoxel is represented by two Gaussian distributions, each of which models a superpixel in one frame. To guarantee temporal consistency, the two Gaussian distributions of a supervoxel share the same color parameters. Every superpixel is assumed to be distributed in a local region, resulting in an algorithm with lower complexity than the traditional GMM. According to our experiments, the proposed method outperforms the state-of-the-art algorithms in terms of segmentation accuracy while possessing a competitive computing performance.
As a contribution to open source society, our test code will be publicly available at https://github.com/ahban.
Author Contributions
Zhihua Ban conceived, designed the experiments and wrote the paper; Zhong Chen and Jianguo Liu contributed analysis tools.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, Z.; Huang, B. Linear Spectral Clustering Superpixel. IEEE Trans. Image Process. 2017, 26, 3317–3330. [Google Scholar] [CrossRef] [PubMed]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed]
- Ban, Z.; Liu, J.; Fouriaux, J. GLSC: LSC superpixels at over 130 FPS. J. Real-Time Image Process. 2016, 1–12. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, K.; Lin, J. An Automatic Localization Algorithm for Ultrasound Breast Tumors Based on Human Visual Mechanism. Sensors 2017, 17, 1101. [Google Scholar]
- Zhang, Q.; Liu, Y.; Zhu, S.; Han, J. Salient object detection based on super-pixel clustering and unified low-rank representation. Comput. Vis. Image Underst. 2017, 161, 51–64. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, J.; Tao, Y.; Li, W.; Shi, Y. Salient object detection via color and texture cues. Neurocomputing 2017, 243, 35–48. [Google Scholar] [CrossRef]
- Van De Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1879–1886. [Google Scholar]
- Zhong, Z.; Lei, M.; Cao, D.; Fan, J.; Li, S. Class-specific object proposals re-ranking for object detection in automatic driving. Neurocomputing 2017, 242, 187–194. [Google Scholar] [CrossRef]
- Liu, J.; Tang, Z.; Cui, Y.; Wu, G. Local Competition-Based Superpixel Segmentation Algorithm in Remote Sensing. Sensors 2017, 17, 1364. [Google Scholar] [CrossRef] [PubMed]
- Qiu, W.; Gao, X.; Han, B. A superpixel-based CRF saliency detection approach. Neurocomputing 2017, 244, 19–32. [Google Scholar] [CrossRef]
- Fu, P.; Li, C.; Cai, W.; Sun, Q. A spatially cohesive superpixel model for image noise level estimation. Neurocomputing 2017, 266, 420–432. [Google Scholar] [CrossRef]
- Reso, M.; Jachalsky, J.; Rosenhahn, B.; Ostermann, J. Temporally Consistent Superpixels. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 385–392. [Google Scholar]
- Liang, Y.; Dong, X.; Shen, J. Supervoxel using random walks. In Proceedings of the 2014 7th International Congress on Image and Signal Processing, Dalian, China, 14–16 October 2014; pp. 120–124. [Google Scholar]
- Xu, C.; Corso, J.J. Evaluation of super-voxel methods for early video processing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1202–1209. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and Supervoxels in an Energy Optimization Framework. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 211–224. [Google Scholar]
- Liang, Y.; Shen, J.; Dong, X.; Sun, H.; Li, X. Video Supervoxels Using Partially Absorbing Random Walks. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 928–938. [Google Scholar] [CrossRef]
- Levinshtein, A.; Sminchisescu, C.; Dickinson, S. Spatiotemporal Closure. In Proceedings of the 10th Asian Conference on Computer Vision (ACCV), Queenstown, New Zealand, 8–12 November 2011; pp. 369–382. [Google Scholar]
- Bergh, M.V.D.; Roig, G.; Boix, X.; Manen, S.; Gool, L.V. Online Video SEEDS for Temporal Window Objectness. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 377–384. [Google Scholar]
- Chang, J.; Wei, D.; Fisher, J.W., III. A Video Representation Using Temporal Superpixels. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2051–2058. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Reynolds, D. Gaussian mixture models. In Encyclopedia of Biometrics; Li, S.Z., Jain, A.K., Eds.; Springer: Boston, MA, USA, 2015; pp. 827–832. [Google Scholar]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized Gaussian fields criterion. Pattern Recognit. 2015, 48, 772–784. [Google Scholar] [CrossRef]
- Ban, Z.; Liu, J.; Cao, L. Superpixel Segmentation Using Gaussian Mixture Model. arXiv, 2016; arXiv:1612.08792. [Google Scholar]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar]
- Grundmann, M.; Kwatra, V.; Han, M.; Essa, I. Efficient hierarchical graph-based video segmentation. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2141–2148. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Xu, C.; Xiong, C.; Corso, J.J. Streaming Hierarchical Video Segmentation. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 626–639. [Google Scholar]
- Van den Bergh, M.; Boix, X.; Roig, G.; de Capitani, B.; Van Gool, L. SEEDS: Superpixels Extracted via Energy-Driven Sampling. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 13–26. [Google Scholar]
- Van den Bergh, M.; Boix, X.; Roig, G.; Van Gool, L. SEEDS: Superpixels Extracted via Energy-Driven Sampling. Int. J. Comput. Vis. 2015, 111, 298–314. [Google Scholar] [CrossRef]
- Chen, A.Y.C.; Corso, J.J. Propagating multi-class pixel labels throughout video frames. In Proceedings of the 2010 Western New York Image Processing Workshop, Rochester, NY, USA, 5 November 2010; pp. 14–17. [Google Scholar]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of Moving Objects by Long Term Video Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1187–1200. [Google Scholar] [CrossRef] [PubMed]
- Brox, T.; Malik, J. Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 282–295. [Google Scholar]
Figure 1.
Two toy examples of supervoxel segmentation on (a) video with new object and (b) video with moving object. The first row are synthetic video frames. The results of two representative state-of-the-art algorithms—PARW [17] and TSP [20]—are plotted in the second and third rows. Our results are shown in the last row. Pixels with the same supervoxel label are painted using the same color, best viewed in color.
Figure 1.
Two toy examples of supervoxel segmentation on (a) video with new object and (b) video with moving object. The first row are synthetic video frames. The results of two representative state-of-the-art algorithms—PARW [17] and TSP [20]—are plotted in the second and third rows. Our results are shown in the last row. Pixels with the same supervoxel label are painted using the same color, best viewed in color.

Figure 2.
An illustration of a possible usage of the proposed method. The first row is three successive frames. In the second row, the first two superpixel segmentations are extracted using only the first two frames. Similarly, the last two superpixel segmentations are extracted using only the last two frames. In this example, the second frame has two superpixel segmentations. The third row explains a possible usage in foreground segmentation or object tracking, best viewed in color.
Figure 2.
An illustration of a possible usage of the proposed method. The first row is three successive frames. In the second row, the first two superpixel segmentations are extracted using only the first two frames. Similarly, the last two superpixel segmentations are extracted using only the last two frames. In this example, the second frame has two superpixel segmentations. The third row explains a possible usage in foreground segmentation or object tracking, best viewed in color.

Figure 3.
Supervoxel segmentation with different values for and . (a) two successive synthetic frames with constant colors; (b) supervoxels with ; (c) supervoxels with ; In both (b) and (c), voxels with the same color form a supervoxel. Although (b) and (c) use different and , the number of the generated supervoxels are the same, but the shapes are very different.
Figure 3.
Supervoxel segmentation with different values for and . (a) two successive synthetic frames with constant colors; (b) supervoxels with ; (c) supervoxels with ; In both (b) and (c), voxels with the same color form a supervoxel. Although (b) and (c) use different and , the number of the generated supervoxels are the same, but the shapes are very different.

Figure 4.
Illustration of anchor region and overlap region with two different settings for and : (a) , (b) , . In this example of both (a) and (b), and the 25 anchor regions are marked with black rectangles. The region within the blue rectangle is the overlap region of supervoxel whose anchor region is highlighted by a red rectangle.
Figure 4.
Illustration of anchor region and overlap region with two different settings for and : (a) , (b) , . In this example of both (a) and (b), and the 25 anchor regions are marked with black rectangles. The region within the blue rectangle is the overlap region of supervoxel whose anchor region is highlighted by a red rectangle.

Figure 5.
Results of 2D metrics. (a) 2D BR; (b) 2D UE; (c) 2D ASA.

Figure 6.
Results of 3D metrics. (a) 3D UE; (b) 3D ASA.

Figure 7.
Comparison of run-time.

Figure 8.
Examples of supervoxel segmentation. (a) PARW [17]; (b) TSP [20]; (c) vSEEDS [19]; (d) ours. The algorithms extract approximately the same number of supervoxels. Superpixel boundaries are plotted in the first, third, fifth, and seventh rows. In the remaining rows, we paint voxels of the same supervoxel using the same color. Disappearing and appearing superpixels are painted using black in the first frames and white in the second frames, respectively. The third, fourth, seventh, and eighth rows zoom in on regions of the first, second, fifth, and sixth rows, respectively.
Figure 8.
Examples of supervoxel segmentation. (a) PARW [17]; (b) TSP [20]; (c) vSEEDS [19]; (d) ours. The algorithms extract approximately the same number of supervoxels. Superpixel boundaries are plotted in the first, third, fifth, and seventh rows. In the remaining rows, we paint voxels of the same supervoxel using the same color. Disappearing and appearing superpixels are painted using black in the first frames and white in the second frames, respectively. The third, fourth, seventh, and eighth rows zoom in on regions of the first, second, fifth, and sixth rows, respectively.

Figure 9.
Segmentation results of a moving target that becomes two separated parts during the moving.
Figure 9.
Segmentation results of a moving target that becomes two separated parts during the moving.

Figure 10.
Segmentation results of a moving target that is partially covered by another object during the moving.
Figure 10.
Segmentation results of a moving target that is partially covered by another object during the moving.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ban, Z.; Chen, Z.; Liu, J. Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model. Sensors 2018, 18, 128. https://doi.org/10.3390/s18010128
AMA Style
Ban Z, Chen Z, Liu J. Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model. Sensors. 2018; 18(1):128. https://doi.org/10.3390/s18010128
Chicago/Turabian StyleBan, Zhihua, Zhong Chen, and Jianguo Liu. 2018. "Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model" Sensors 18, no. 1: 128. https://doi.org/10.3390/s18010128
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.