



Algorithms 2024, 17(5), 188; https://doi.org/10.3390/a17050188 (registering DOI) - 29 Apr 2024
Abstract
Implementing approaches based on process mining in inter-organizational collaboration environments presents challenges related to the granularity of event logs, the privacy and autonomy of business processes, and the alignment of event data generated in inter-organizational business process (IOBP) execution. Therefore, this paper proposes
[...] Read more.
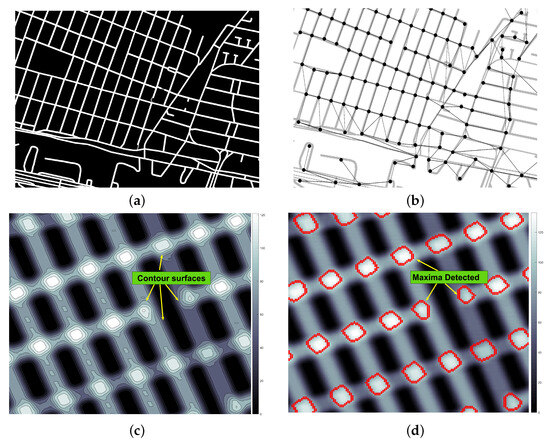
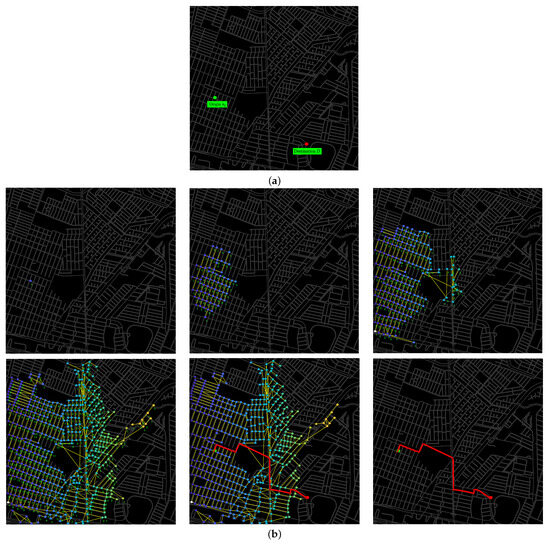
Implementing approaches based on process mining in inter-organizational collaboration environments presents challenges related to the granularity of event logs, the privacy and autonomy of business processes, and the alignment of event data generated in inter-organizational business process (IOBP) execution. Therefore, this paper proposes a complete and modular data-driven approach that implements natural language processing techniques, text similarity, and process mining techniques (discovery and conformance checking) through a set of methods and formal rules that enable analysis of the data contained in the event logs and the intra-organizational process models of the participants in the collaboration, to identify patterns that allow the discovery of the process choreography. The approach enables merging the event logs of the inter-organizational collaboration participants from the identified message interactions, enabling the automatic construction of an IOBP model. The proposed approach was evaluated using four real-life and two artificial event logs. In discovering the choreography process, average values of 0.86, 0.89, and 0.86 were obtained for relationship precision, relation recall, and relationship F-score metrics. In evaluating the quality of the built IOBP models, values of 0.95 and 1.00 were achieved for the precision and recall metrics, respectively. The performance obtained in the different scenarios is encouraging, demonstrating the ability of the approach to discover the process choreography and the construction of business process models in inter-organizational environments.
Full article
(This article belongs to the Special Issue Data-Driven Intelligent Modeling and Optimization Algorithms for Industrial Processes)

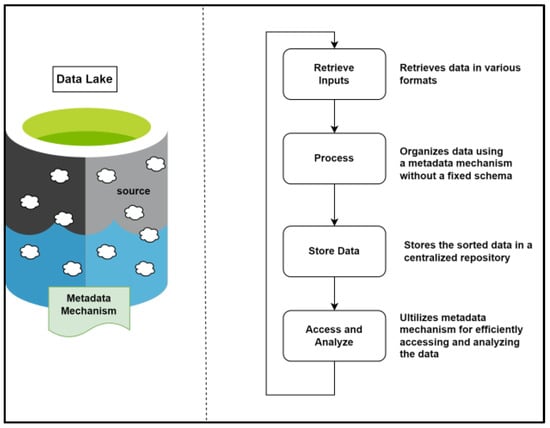





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}