Parallelizing Particle Swarm Optimization in a Functional Programming Environment


Abstract
:1. Introduction
- (a)
- The functional paradigm allows programmers to write clean and highly reusable programs with a relatively low effort.
- (b)
- The skeletons can be used to quickly test the performance of different versions of parallel PSO for the a given problem, thus helping the programmer to decide whether PSO (or a given parallel PSO approach) is the right choice for her problem. Together with other parallel functional skeletons for other metaheuristics (e.g., a skeleton for genetic algorithms was introduced in [31]), programmers will be able to quickly test different parallel metaheuristics for a given problem, compare them, and pick the most appropriate one.
- (c)
- Using the skeletons does not require programming in Eden, since Eden can invoke functions written in other languages. For instance, after a programmer provides a fitness function written in C, all of these skeletons are ready to be executed.
2. Functional Languages under Consideration
2.1. Brief Introduction to Haskell
data Tree a = Empty | Node a (Tree a) (Tree a)
length :: Tree a -> Int
length Empty = 0
length (Node x t1 t2) = 1 + length t1 + length t2
infTree :: Tree Int
infTree = Node 1 infTree infTree
and the following function to know whether a binary tree is empty or not:
emptyTree :: Tree a -> Bool
emptyTree Empty = True
emptyTree (Node a b c) = False
Knowing whether the binary tree
(Node 1) infTree infTree
is empty or not is possible because, thanks to laziness, both subexpressions infTree of
emptyTree ((Node 1)infTree infTree)
remain unevaluated.
map :: (a -> b) -> [a] -> [b]
map f [] = []
map f (x:xs) = (f x):(map f xs)
map :: (a -> b) -> [a] -> [b]
map f xs = [f x | x <- xs]
mapPlusOne :: [Int] -> [Int]
mapPlusOne xs = map (1+) xs
Thus, it adds one to each element of the list.
sort :: Ord a => [a] -> [a]
sort [] = []
sort (x:xs) = (sort [y|y<-xs,y<x]) ++ [x] ++ (sort[y|y<-xs,y>=x])
2.2. Introduction to Eden
2.3. Eden Skeletons
map f xs = [f x | x <- xs]
that can be read as for each element x belonging to the list xs, apply function f to that element. This can be trivially parallelized in Eden. In order to use a different process for each task, we will use the following approach:
map_par f xs = [pf # x | x <- xs] `using` spine
where pf = process f
The process abstraction pf wraps the function application (f x). It determines that the input parameter x as well as the result value will be transmitted through channels. The spine strategy (see [16] for details) is used to eagerly evaluate the spine of the process instantiation list. In this way, all processes are immediately created. Otherwise, they would only be created on demand.3. Introduction to Particle Swarm Optimization
(Initialization) For i = 1,…,S Do initPosition(i) initBestLocal(i) If i = 1 Then initBestGlobal() If improvedGlobal(i) Then updateBestGlobal(i) initVelocity(i) End For (While loop) While not endingCondition() For i = 1,…,S Do createRnd(rp,rg) updateVelocity(i,rp,rg) updatePosition(i) If improvedLocal(i) Then updateBestLocal(i) If improvedGlobal(i) Then updateBestGlobal(i) End For End While
4. Generic PSO Algorithms in Haskell
pso :: RandomGen a => a --Random generator
-> WPGparams --ω, ϕ p and ϕ r
-> Int --Number of particles
-> Int --Number of iterations
-> (Position->Double) --Fitness function
-> Boundaries --Search space bounds
-> (Double,Position) --Result:Best fitness and position
type Position = [Double]
type Boundaries = [(Double,Double)]
type WPGparams = (Double, Double, Double)
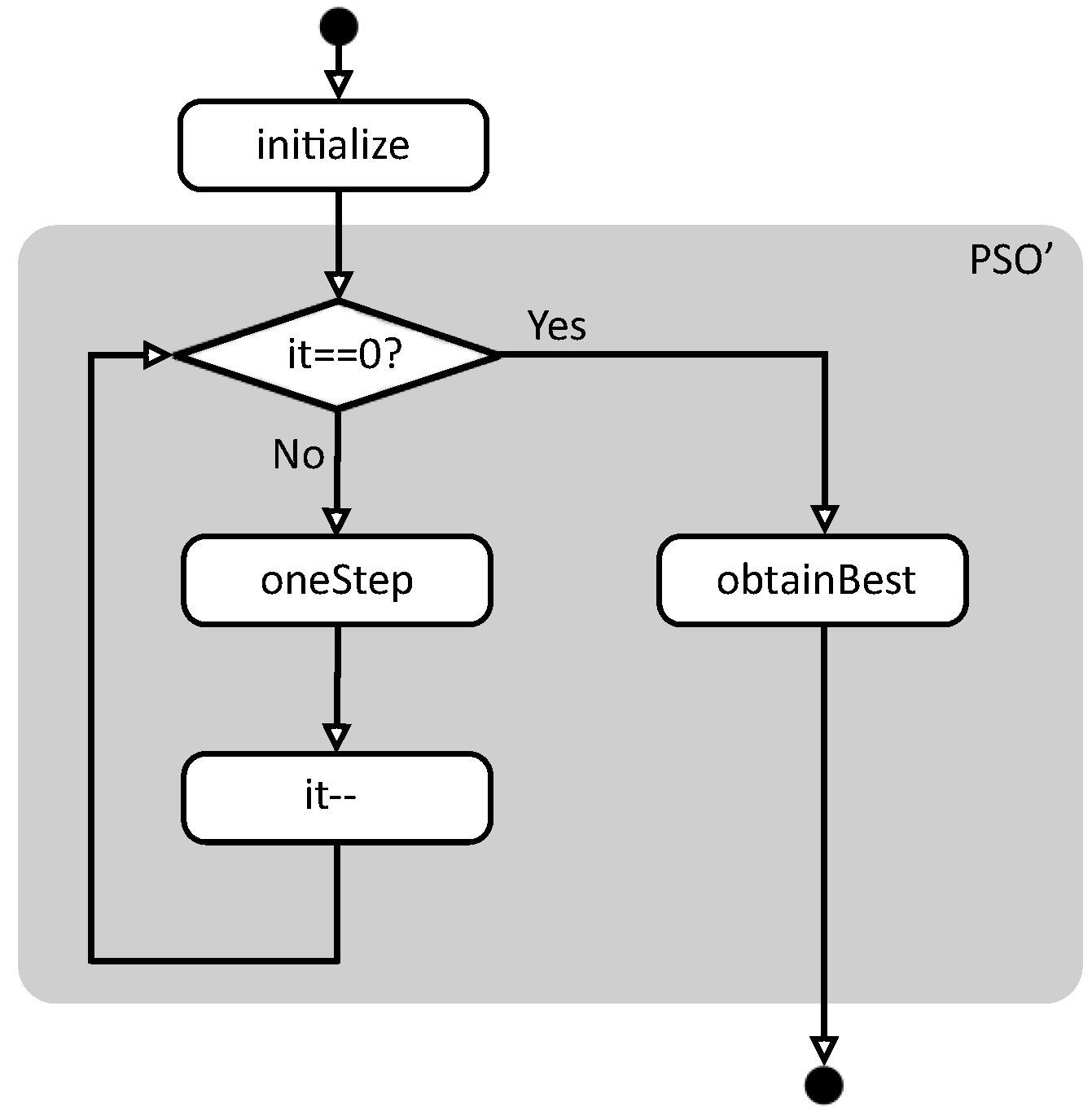
pso sg wpg np it f bo = obtainBest (pso’ rss wpg it f bo initPs)
where initPs = initialize sg np bo f
rss = makeRss np (randomRs (0, 1) sg)
--Particle: Best local value, best global value, current position and
--velocity, best local position, best global position
type Particle = (Double,Double,Position,Velocity,Position,Position)
type Velocity = [Double]
pso’ _ _ 0 _ _ pas = pas
pso’ (rs:rss) wpg it f bo pas = pso’ rss wpg (it-1) f bo
(oneStep rs wpg f bo pas)
oneStep :: [(Double,Double)] -> WPGparams -> (Position -> Double)
-> Boundaries -> [Particle] -> [Particle]
oneStep rs wpg f bo pas
|null newBests = newPas
|otherwise = map(updateGlobalBest newBvBp)newPas
where newBsPas = zipWith (updateParticle wpg f bo) rs pas
newPas = map snd newBsPas
newBests = map snd (filter fst newBsPas)
newBvBp = obtainBest [minimum newBests]
updateParticle :: WPGparams ->(Position->Double)->Boundaries
->(Double,Double)->Particle->(Bool,Particle)
updateParticle (w,p,g) f bo (rp,rg) (blv,bgv,po,s,blp,bgp)
|newFit < bgv = (True,(newFit,newFit,newPos,newVel,newPos,newPos))
|newFit < blv = (False,(newFit,bgv,newPos,newVel,newPos,bgp))
|otherwise = (False,(blv,bgv,newPos,newVel,blp,bgp))
where newVel = w*&s +& p*rp*&(blp-&po) +& g*rg*&(bgp-&po)
newPos = limitRange bo (po +& newVel)
newFit = f newPos
where +& and -& perform the sum and difference on arbitrary large vectors, while *& multiplies all the elements of a vector by a single real number.
fit :: Position -> Double
fit xs = sum (map fit’ xs) where fit’ xi = -xi * sin (sqrt (abs xi))
bo :: Boundaries
bo = replicate 30 (-500,500)
5. PSO Parallel Skeletons in Eden
5.1. A Simple Parallel Skeleton
oneStep rs wpg f bo pas
| null newBests = newPas
| otherwise = map (updateGlobalBest newBvBp) newPas
where newBsPas = map_par updatingP (zip rs pas)
updatingP = uncurry (updateParticle wpg f bo)
newPas = map snd newBsPas
newBests = map snd (filter fst newBsPas)
newBvBp = obtainBest [minimum newBests]
...
newBsPas = map_farm noPe updatingP (zip rs pas)
...
where noPe is an Eden variable which equals to the number of available processors in the system, while map_farm implements the idea of distributing a large list of tasks among a reduced number of processes. The implementation firstly distributes the tasks among the processes, producing a list of lists where each inner list will be executed by an independent process. Then, it applies map_par, and finally it collects the results by joining the list of lists of results into a single list of results. Notice that, due to the laziness, these three tasks are not done sequentially, but in interleaving. As soon as any worker computes one of its outputs, it sends this subresult to the main process, and it continues computing the next element of the output list. Notice that communications are asynchronous, so it is not necessary to wait for acknowledgments from the main process. When the main process has received all needed results, it finishes the computation. The Eden source code of this skeleton is shown below, where not only the number of processors np but also the distribution and collection functions (unshuffle and shuffle respectively) are also parameters of the skeleton:
map_farmG np unshuffle shuffle f xs
= shuffle (map_par (map f) (unshuffle np xs))
5.2. A Parallel Skeleton Reducing Communications
psoPAR :: RandomGen a => a --Random generator
-> WPGparams --ω, ϕ p and ϕ r
-> Int --Number of particles
-> Int --Iterations per parallel step
-> Int --Number of parallel iterations
-> Int --Number of parallel processes
-> (Position -> Double) --Fitness function
-> Boundaries --Search space bounds
-> (Double,Position) --Result: Best fitness and position
psoP :: RandomGen a => a --Random generator
-> WPGparams --ω, ϕ p and ϕ r
-> Int --Iterations per parallel step
-> (Position -> Double) --Fitness function
-> Boundaries --Search space bounds
-> ([Particle],[(Double,Position)]) --Initial local particles,
--best overall solutions
-> [(Double,Position)] --Out:Best local solutions
psoP sg wpg pit f bo (pas,[]) = []
psoP sg wpg pit f bo (pas,newBest:newBests)
= newOut:psoP sg2 wpg pit f bo (newPas,newBests)
where rss = makeRss (length pas) (randomRs (0,1) sg1)
(sg1,sg2) = split sg
pas’ = if newBest < oldBest
then map (updateGlobalBest newBest) pas
else pas
newPas = pso’_ rss wpg pit f bo pas’
newOut = obtainBest newPas
oldBest = obtainBest pas
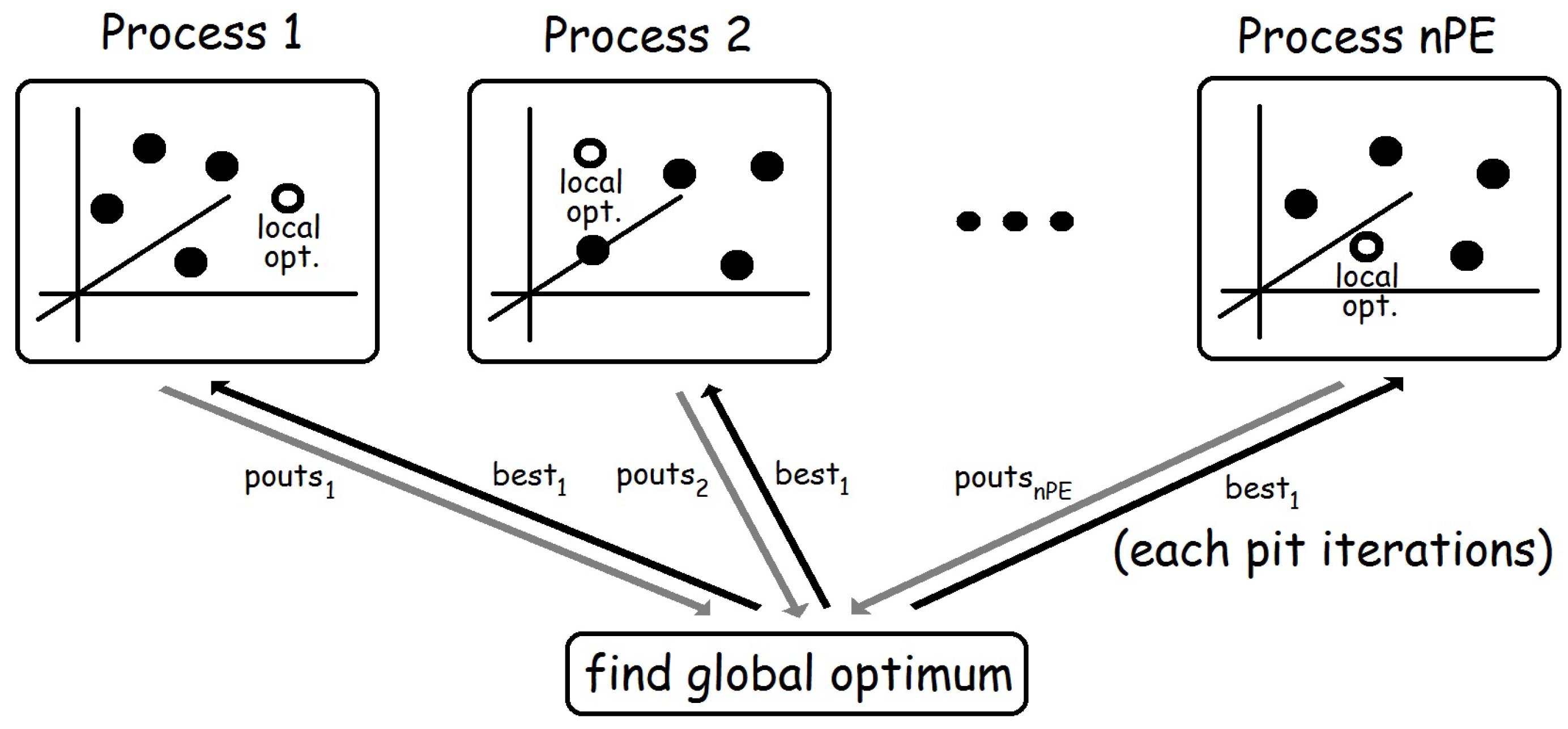
psoPAR sg wpg np pit it nPE f bo = last bests
where initPs = initialize sg np bo f
pass = unshuffle nPE initPs
sgs = tail (generateSGs (nPE+1) sg)
pouts :: [ [(Double,Position)] ]
pouts = [process (psoP (sgs!!i) wpg pit f bo)#(pass!!i,bests1)
|i<-[0..nPE-1]] `using` spine
bests,bests1 :: [(Double,Position)]
bests = map minimum (transp pouts)
bests1 = take it (obtainBest initPs : bests)

5.3. Alternative Skeletons
psoPARh :: RandomGen a => a --Random generator
-> WPGparams --ω, ϕp and ϕr
-> Int --Number of particles
-> Int --Iterations per parallel step
-> Int --Number of parallel iterations
-> [Double] --Speed of processors
-> (Position -> Double) --Fitness function
-> Boundaries --Search space bounds
-> (Double,Position) --Result: Best fitness and position
psoPARh sg wpg np pit it speeds f bo = last bests
where initPs = initialize sg np bo f
nPE = length speeds
pass = shuffleRelative speeds initPs
sgs = tail (generateSGs (nPE+1) sg)
pouts :: [ [(Double,Position)] ]
pouts =[process (psoP (sgs!!i) wpg pit f bo) #(pass!!i,bests1)
|i<-[0..nPE-1]] `using` spine
bests,bests1 :: [(Double,Position)]
bests = map minimum (transp pouts)
bests1 = take it (obtainBest initPs : bests)
shuffleRelative speeds tasks = splitWith percentages tasks
where percentages=map (round.(m*).(/total)) speeds
total = sum speeds
m = fromIntegral (length tasks)
splitWith [n] xs = [xs]
splitWith (n:ns) xs = firsts:splitWith ns rest
where (firsts,rest) = splitAt n xs
psoPARvh :: RandomGen a => a --Random generator
-> WPGparams --ω, ϕp and ϕr
-> Int --Number of particles
-> [Int] --Iterations in each parallel step
-> [Double] --Speed of processors
-> (Position -> Double) --Fitness function
-> Boundaries --Search space bounds
-> (Double,Position) --Result: Best fitness and position
and its new definition only has to appropriately compute the previous parameter it (number of global synchronizations) and pass the new list parameter pits to a new process psoPv:
psoPARvh sg wpg np pits speeds f bo = last bests
where ...
it = length pits
pouts=[process (psoPv (sgs!!i) wpg pits f bo)#(pass!!i,bests1)
|i<-[0..nPE-1]] `using` spine
...
psoPv sg wpg (pit:pits) f bo (pas,newBest:newBests)
= newOut : psoPv sg2 wpg pits f bo (newPas,newBests)
where ...
newPas = pso’ rss wpg pit f bo pas’
...
6. Experimental Results
6.1. Experimental Setup
- Sphere Model:
- Schwefel’s Problem :
- Schwefel’s Problem :
- Schwefel’s Problem :
- Generalized Rosenbrock’s Function:
- Step Function:
- Generalized Schwefel’s Problem :
- Generalized Rastrigin’s Function:
- Ackley’s Function:
- Generalized Griewank Function:
- Generalized Penalized Function I: , ,
- Generalized Penalized Function II:
- Shekel’s Foxholes Function:
- Kowalik’s Function:
- Six-Hump Camel-Back Function:
- Branin Function:

{kind=link}
{kind=link}
{kind=link}
| Function | Dimensions (n) | Asym. Init. Range | ||
|---|---|---|---|---|
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | ||||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 30 | 0 | |||
| 2 | 1 | |||
| 4 | 0.0003075 | |||
| 2 | −1.0316285 | |||
| 2 | 0.398 |
6.2. Analyzing the Influence of Using Islands
| Function | 1 Island | 2 Islands | 3 Islands | 4 Islands |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | |
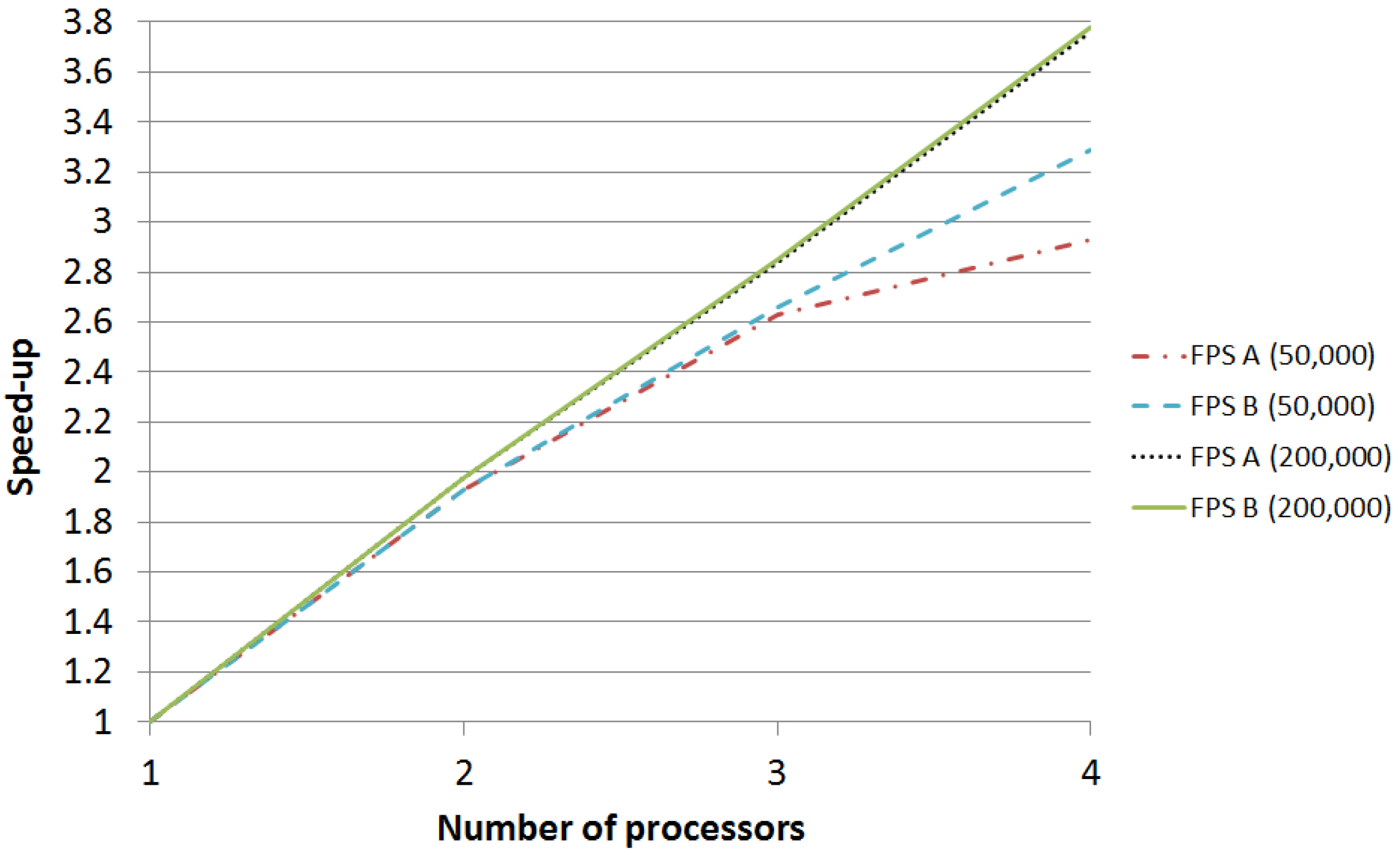
6.3. Speedup Analysis
| Function | Iterations | Best Sol | Arith Mean | Std Dev |
|---|---|---|---|---|
| 9000 | ||||
| Version | Iterations | Processors | Time | Speedup |
|---|---|---|---|---|
| FPS | 1 | 1 | ||
| FPS A | 2 | |||
| FPS B | 2 | |||
| FPS A | 3 | |||
| FPS B | 3 | |||
| FPS A | 4 | |||
| FPS B | 4 | |||
| FPS | 1 | 1 | ||
| FPS A | 2 | |||
| FPS B | 2 | |||
| FPS A | 3 | |||
| FPS B | 3 | |||
| FPS A | 4 | |||
| FPS B | 4 |

7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Eiben, A.; Smith, J. Introduction to Evolutionary Computing; Springer: Heidelberg, Germany, 2003. [Google Scholar]
- Chiong, R. Nature-Inspired Algorithms for Optimisation; Chiong, R., Ed.; Springer: Heidelberg, Germany, 2009; Volume 193. [Google Scholar]
- Kennedy, J.; Eberhart, R. Swarm Intelligence; The Morgan Kaufmann Publishers: San Francisco, USA, 2001. [Google Scholar]
- Kennedy, J. Swarm Intelligence. In Handbook of Nature-Inspired and Innovative Computing; Zomaya, A., Ed.; Springer: New York, USA, 2006; pp. 187–219. [Google Scholar]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed]
- Rabanal, P.; Rodríguez, I.; Rubio, F. Using River Formation Dynamics to Design Heuristic Algorithms. In Unconventional Computation, Proceedings of the 6th International Conference, UC 2007, Kingston, ON, Canada, 13–17 Augurst 2007; Springer: Heidelberg, Germany, 2007; pp. 163–177. [Google Scholar]
- Civicioglu, P.; Besdok, E. A conceptual comparison of the Cuckoo-search, particle swarm optimization, differential evolution and artificial bee colony algorithms. Artif. Intell. Rev. 2013, 39, 315–346. [Google Scholar] [CrossRef]
- Cantú-Paz, E. A Survey of Parallel Genetic Algorithms. Calc. Parall. Reseaux Syst. Repartis 1998, 10, 141–171. [Google Scholar]
- Alba, E. Parallel evolutionary algorithms can achieve super-linear performance. Inf. Process. Lett. 2002, 82, 7–13. [Google Scholar] [CrossRef]
- Randall, M.; Lewis, A. A Parallel Implementation of Ant Colony Optimization. J. Parallel Distrib. Comput. 2002, 62, 1421–1432. [Google Scholar] [CrossRef]
- Nedjah, N.; de Macedo-Mourelle, L.; Alba, E. Parallel Evolutionary Computations; Nedjah, N., de Macedo-Mourelle, L., Alba, E., Eds.; Studies in Computational Intelligence, Springer: Heidelberg, Germany, 2006; Volume 22. [Google Scholar]
- Zhou, Y.; Tan, Y. GPU-based parallel particle swarm optimization. In Proceedings of the Eleventh Conference on Congress on Evolutionary Computation, Trondheim, Norway, 18–21 May 2009; IEEE Press: Piscataway, USA, 2009; pp. 1493–1500. [Google Scholar]
- Mussi, L.; Daolio, F.; Cagnoni, S. Evaluation of parallel particle swarm optimization algorithms within the CUDA (TM) architecture. Inf. Sci. 2011, 181, 4642–4657. [Google Scholar] [CrossRef]
- Achten, P.; van Eekelen, M.; Koopman, P.; Morazán, M. Trends in Trends in Functional Programming 1999/2000 versus 2007/2008. High.-Order Symb. Comput. 2010, 23, 465–487. [Google Scholar] [CrossRef]
- Cole, M. Bringing Skeletons out of the Closet: A Pragmatic Manifesto for Skeletal Parallel Programming. Parallel Comput. 2004, 30, 389–406. [Google Scholar] [CrossRef]
- Trinder, P.W.; Hammond, K.; Loidl, H.W.; Peyton Jones, S.L. Algorithm + Strategy = Parallelism. J. Funct. Programm. 1998, 8, 23–60. [Google Scholar] [CrossRef]
- Klusik, U.; Loogen, R.; Priebe, S.; Rubio, F. Implementation Skeletons in Eden: Low-Effort Parallel Programming. In Proceedings of the 12th International Workshop on the Implementation of Functional Languages, IFL 2000, Aachen, Germany, 4–7 September 2000; Springer: Heidelberg, Germany, 2001; pp. 71–88. [Google Scholar]
- Scaife, N.; Horiguchi, S.; Michaelson, G.; Bristow, P. A Parallel SML Compiler Based on Algorithmic Skeletons. J. Funct. Programm. 2005, 15, 615–650. [Google Scholar] [CrossRef]
- Marlow, S.; Peyton Jones, S.L.; Singh, S. Runtime Support for Multicore Haskell. In Proceedings of the International Conference on Functional Programming, ICFP’09, Edinburgh, Scotland, 31 August–2 September 2009; pp. 65–78.
- Keller, G.; Chakravarty, M.; Leshchinskiy, R.; Peyton Jones, S.; Lippmeier, B. Regular, shape-polymorphic, parallel arrays in Haskell. In Proceedings of the International Conference on Functional Programming (ICFP’10), Baltimore, Maryland, 27–29 September 2010; pp. 261–272.
- Marlow, S. Parallel and Concurrent Programming in Haskell: Techniques for Multicore and Multithreaded Programming; O’Reilly Media, Inc.: Sebastopol, USA, 2013. [Google Scholar]
- Loogen, R.; Ortega-Mallén, Y.; Peña, R.; Priebe, S.; Rubio, F. Parallelism Abstractions in Eden. In Patterns and Skeletons for Parallel and Distributed Computing; Rabhi, F.A., Gorlatch, S., Eds.; Springer: London, UK, 2002; pp. 95–128. [Google Scholar]
- Peyton Jones, S.L.; Hughes, J. Report on the Programming Language Haskell 98. Technical report, Microsoft Research (Cambridge) and Chalmers University of Technology, 1999. Available online: http://www.haskell.org (accessed on 22 October 2014).
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks; IEEE Computer Society Press: Piscataway, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the IEEE International Conference on Evolutionary Computation; IEEE Computer Society Press: Piscataway, USA, 1998; pp. 69–73. [Google Scholar]
- Clerc, M.; Kennedy, J. The particle swarm—Explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evolut. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef]
- Parsopoulos, K.; Vrahatis, M. Recent approaches to global optimization problems through Particle Swarm Optimization. Nat. Comput. 2002, 1, 235–306. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Zhang, J.; Li, Y.; Chung, H.H. Adaptive Particle Swarm Optimization. IEEE Trans. Syst. Man Cybern. 2009, 39, 1362–1381. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, M. Tuning & Simplifying Heuristical Optimization. PhD Thesis, University of Southampton, Southampton, UK, 2010. [Google Scholar]
- Abido, M. Multiobjective particle swarm optimization with nondominated local and global sets. Nat. Comput. 2010, 9, 747–766. [Google Scholar] [CrossRef]
- Encina, A.V.; Hidalgo-Herrero, M.; Rabanal, P.; Rubio, F. A Parallel Skeleton for Genetic Algorithms. In Proceedings of the International Work-Conference on Artificial Neural Networks, IWANN 2011; Springer: Heidelberg, 2011; pp. 388–395. [Google Scholar]
- Goldberg, D. Genetic Algorithms in Search, Optimisation and Machine Learning; Addison-Wesley: Boston, USA, 1989. [Google Scholar]
- Hidalgo-Herrero, M.; Ortega-Mallén, Y.; Rubio, F. Analyzing the influence of mixed evaluation on the performance of Eden skeletons. Parallel Comput. 2006, 32, 523–538. [Google Scholar] [CrossRef]
- Eberhart, R.; Simpson, P.; Dobbins, R. Computational Intelligence PC Tools; Academic Press Professional: San Diego, USA, 1996. [Google Scholar]
- Kennedy, J. Small worlds and mega-minds: Effects of neighborhood topology on particle swarm performance. In Congress on Evolutionary Computation; IEEE Computer Society Press: Piscataway, USA, 1999; Volume 3, pp. 1931–1938. [Google Scholar]
- Shi, Y.; Eberhart, R. Parameter Selection in Particle Swarm Optimization. In Evolutionary Programming; LNCS; Springer: Heidelberg, Germany, 1998; Voloume1447, pp. 591–600. [Google Scholar]
- Beielstein, T.; Parsopoulos, K.; Vrahatis, M. Tuning PSO parameters through sensitivity analysis. Technical report. Universität Dortmund: Germany, 2002. [Google Scholar]
- Laskari, E.C.; Parsopoulos, K.E.; Vrahatis, M.N. Particle Swarm Optimization for Integer Programming. In IEEE Congress on Evolutionary Computation; IEEE Computer Society Press: Piscataway, USA, 2002; pp. 1576–1581. [Google Scholar]
- Yao, X.; Liu, Y.; Lin, G. Evolutionary programming made faster. IEEE Trans. Evolut. Comput. 1999, 3, 82–102. [Google Scholar]
- Worasucheep, C. A particle swarm optimization for high-dimensional function optimization. In Proceedings of the International Conference on Electrical Engineering/Electronics Computer Telecommunications and Information Technology (ECTI-CON’10); IEEE Computer Society Press: Piscataway, USA, 2010; pp. 1045–1049. [Google Scholar]
- Parejo-Maestre, J.; García-Gutiérrez, J.; Ruiz-Cortés, A.; Riquelme-Santos, J. STATService. Available online: http://moses.us.es/statservice/ (accessed on 22 October 2014).
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 674–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Hodges, J.; Lehmann, E. Ranks methods for combination of independent experiments in analysis of variance. Ann. Math. Stat. 1962, 33, 482–497. [Google Scholar] [CrossRef]
- Quade, D. Using weighted rankings in the analysis of complete blocks with additive block effects. J. Am. Stat. Assoc. 1979, 74, 680–683. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rabanal, P.; Rodríguez, I.; Rubio, F. Parallelizing Particle Swarm Optimization in a Functional Programming Environment. Algorithms 2014, 7, 554-581. https://doi.org/10.3390/a7040554
Rabanal P, Rodríguez I, Rubio F. Parallelizing Particle Swarm Optimization in a Functional Programming Environment. Algorithms. 2014; 7(4):554-581. https://doi.org/10.3390/a7040554
Chicago/Turabian StyleRabanal, Pablo, Ismael Rodríguez, and Fernando Rubio. 2014. "Parallelizing Particle Swarm Optimization in a Functional Programming Environment" Algorithms 7, no. 4: 554-581. https://doi.org/10.3390/a7040554